

线程模型与协程/用户级线程
相信在学习OS的时候都见过这样的一个知识点 :
操作系统线程模型
线程模型是用户线程和内核线程之间的关联方式,常见的线程模型有这三种:
一对一(一个用户线程对应一个内核线程)
多对一(多个用户线程映射到一个内核线程)
多对多(多个用户线程映射到多个内核线程)
这是今天在看Java八股文的时候遇到的, 最开始学习OS的时候是不太清楚用户线程与内核线程的概念的。
后来慢慢学习(Golang)知道了协程的概念。
都知道协程是轻量级的线程,相比线程可以减少大量的上下文切换操作(比如内存映像,Cache等等),并且通过编程语言可以实现方便的调度。
这协程跟上面的用户线程的优点为何如此相似??
揣带着疑问, 这里提出几个问题:
资源分配的单位是进程, 调度单位是线程, 那么这里的线程是指的是 用户线程 还是 内核线程 ?
假如目前采用的线程模型比例为 内核线程 : 用户线程 = 1:N , 那么这里调度的对象为? 用户线程通过什么调度?
假如目前采用的线程模型比例为 内核线程 : 用户线程 = 1:N , 则N中其他的用户线程算什么? 是否是协程?
进程&线程&协程
进程
线程
协程
定义
资源分配和拥有的基本单位
程序执行的基本单位
用户态的轻量级线程,线程内部调度的基本单位
切换情况
进程CPU环境(栈、寄存器、页表和文件句柄等)的保存以及新调度的进程CPU环境的设置
保存和设置程序计数器、少量寄存器和栈的内容
先将寄存器上下文和栈保存,等切换回来的时候再进行恢复
切换者
操作系统
操作系统
用户
切换过程
用户态->内核态->用户态
用户态->内核态->用户态
用户态(没有陷入内核)
调用栈
内核栈
内核栈
用户栈
拥有资源
CPU资源、内存资源、文件资源和句柄等
程序计数器、寄存器、栈和状态字
拥有自己的寄存器上下文和栈
并发性
不同进程之间切换实现并发,各自占有CPU实现并行
一个进程内部的多个线程并发执行
同一时间只能执行一个协程,而其他协程处于休眠状态,适合对任务进行分时处理
系统开销
切换虚拟地址空间,切换内核栈和硬件上下文,CPU高速缓存失效、页表切换,开销很大
切换时只需保存和设置少量寄存器内容,因此开销很小
直接操作栈则基本没有内核切换的开销,可以不加锁的访问全 ...

SpringBoot项目使用jmh进行接口基准测试
JMH(Java Microbenchmark Harness)是一个 Java 工具,用于构建、运行和分析用 Java 和其他针对 JVM 的语言编写的 纳米/微米/毫/宏观 基准测试,而且是由Java虚拟机团队开发的。简单说,就是用来测量代码运行性能。
JMH官网:https://openjdk.org/projects/code-tools/jmh/
JMH源码下载:https://github.com/openjdk/jmh
JMH示例代码:https://github.com/openjdk/jmh/tree/1.36/jmh-samples/src/main/java/org/openjdk/jmh/samples
JMeter可能是最常用的性能测试工具。它既支持图形界面,也支持命令行,属于黑盒测试的范畴,对非开发人员比较友好,上手也非常容易。
图形界面一般用于编写、调试测试用例,而实际的性能测试建议还是在命令行下运行。
很多场景下JMeter和JMH都可以做性能测试,但是对于严格意义上的基准测试来说,只有JMH才适合。JMeter的测试结果精度相对JVM较低、所以JMeter不适合于类级别的基准测试,更适合于对精度要求不高、耗时相对较长的操作。
JMeter测试精度差: JMeter自身框架比较重,举个例子:使用JMH测试一个方法,平均耗时0.01ms,而使用JMeter测试的结果平均耗时20ms,相差200倍。
JMeter内置很多采样器:JMeter内置了支持多种网络协议的采样器,可以在不写Java代码的情况下实现很多复杂的测试。JMeter支持集群的方式运行,方便模拟多用户、高并发压力测试。
JMeter适合一些相对耗时的集成功能测试,如API接口的测试。JMH适合于类或者方法的单元测试。
JMH非常好的一点是我们非常灵活: 我们可以手动来编写测试的代码。
比如
1234@Benchmarkpublic void test() { this.controller.getRandomPoet();}
准备工作
导入依赖
123456789101112<dependency> <groupId>org.openjdk.jmh</groupId> <artifactId>jmh- ...

TurboAPI-SDK自动生成技术与代码实践
参考文章为 :
https://tech.meituan.com/2023/01/05/openplatform-sdk-auto-generate.html
文中最后的执行流程是 :
监听接口元数据 -> 触发hook -> 执行代码生成 -> 更新到代码仓库 -> 自动化测试 -> CI/CD -> 发布到仓库(maven等)
核心的内容在于 代码生成 (因为后面的运维工作不太熟悉, 思考如何简化实现)
关于技术选型,考虑
Thymeleaf
FreeMarker
简单的对比了二者,最终选择FreeMarker(前者需要web环境,并且FreeMarkeri语法更加友好,上手难度相对低)。
遇到的问题 :
ftl无法存储空格, 需要通过 ${"\t"} 来渲染 , 手动添加 制表符 是不可能的 , 代码改变世界! 这里的解决方案是写了一个FileUtil , 在准备完ftl文件之后调用一下就可以了
接口元信息 : 如果只是简单的接口调用, 那么还是非常简单的。但是自动化的SDK代码生成需要考虑到各种的情况 , 然后制定某种规范,比如
方法名称问题
import导入问题
参数问题
请求方式问题
这些都是需要考虑的, 同时我也总结了对应的方案(部分方案可能比较蠢,不过代码能正确的跑通就可以)
关于方法名称以及参数,需要扩展interface表, 添加上对应的字段(前面的设计中已经对 固定数据 和 变化数据进行分表了 , 因此还是比较轻松的)
ftl文件编写的问题(由于不熟悉别的语言 , 因此这里只能暂时编写java 版本的SDK模板, 但是也遇到了很多的问题, 大多是在系统设计上)
关于FreeMarker的语法 , 需要知道
获取值 : ${}
转义字符 : ${“\t”}
if - else : <#if ***> </#if> , 中间可以加上 <#elseif> , 如果需要判空, 使用 <#if api.sdkParamName?has_content>
list : <#list apis as api> </#list> 即可 , 其中 apis是上下文的参数
这里给出一份参数示例:
1234567891011 ...

乐观锁事务失效导致数据异常的问题(Spring事务传播)
起因是在使用mybatis-plus的乐观锁插件的时候 , 遇到了问题
mybatis-plus插件官网: https://baomidou.com/pages/0d93c0/#optimisticlockerinnerinterceptor
项目中的配置做法是:
在IOC中注入乐观锁插件Bean
在实体类以及数据库表中添加version字段 , 同时在实体类字段中加上 @Version注解
实现 VersionService , 继承com.baomidou.mybatisplus.extension.service.impl.ServiceImpl , 重写 updateById方法
其他的Service或者Manager层在实现的时候, 继承VersionServiceImpl而不是 mybatis的 ServiceImpl
这样做可以保证其他的 manager 更新数据的时候使用乐观锁进行更新
VersionServiceImpl 的 代码框架如下 , 这里隐含了一个问题 , 等到后面进行说明。
12345678910111213141516171819@Slf4jpublic class VersionServiceImpl<M extends BaseMapper<T>, T> extends ServiceImpl<M, T> { private Integer maxRetryTimes; @Transactional(isolation = Isolation.READ_COMMITTED) @Override public boolean updateById(T entity) { //... try { for (int i = 0; i <= this.maxRetryTimes; i++) { // do retry if (super.updateById(entity)) { return true; } } } //.... ...

关于NIO与OS的思考
起因
最近在学习分布式课程的时候 , 涉及到ZK实现可扩展锁的章节 , 提到了 事件驱动 与 多线程 , 很自然的联想到了NIO有关的知识。
想起来之前在纠结的一个问题 :
NIO以为这 No Blocking I/O , 也就是我们当前的线程不会继续等待本次的I/O事件 , 那么究竟是谁在执行这里的I/O? 这里I/O是否会占用线程/进程的时间片?
首先我们假设,NIO不会占用线程/进程的时间片, 并且这里的I/O操作是由于OS中的组件完成的,
在此之前简单回顾NIO 与 OS 相关的知识。
NIO基础
更详细的内容请参考 : https://blog.dhx.icu/2023/05/netty/Netty网络编程(1)JavaNIO-1[Netty]/
Java NIO(New I/O)是从Java 1.4版本开始引入的一个新的I/O API,可以用于替代标准的Java I/O API。
NIO与原来的I/O有同样的作用和目的,但是使用的方式完全不同,NIO支持面向缓冲区的、基于通道的I/O操作。
NIO
I/O
面向流(Stream Oriented)
面向缓冲区(Buffer Oriented)
阻塞I/O(Blocking I/O)
非阻塞I/O(Non Blocking I/O)
选择器(Selectors
NIO的设计还是为了数据传输。对于channel,如果说之前的文件流类似于水流,那么channel就类似于铁路。对于铁路本身,他是不能直接传输数据的,需要我们配备上火车车厢,而channel的作用就是连接初始地点以及目标地点。因此注意通道本身不能传输数据,要想传输数据必须要有缓冲区。如果你想要把数据写入到文件中,那么就可以先把部分的数据写入到缓冲区中, 通过通道把这部分数据运输到目标的文件,反之亦然。因此说现在的面向缓冲区的传输方式是双向的。
Talk is cheap , show me the code
下面是Java的NIO API简单示例
123456789101112131415161718192021222324public static void main(String[] args) throws I/OExceptI/On { // 访问文件, mode为 read & writ ...

websocket+SseEmitter实现讯飞星火Java客户端
本篇文章主要记录完成 对接讯飞星火的Java 客户端 (适配于Spring) , 方便在之后项目开发的过程中进行快速接入
星火认知大模型Web API文档 : https://www.xfyun.cn/doc/spark/Web.html#_1-接口说明
websocket
简介
在此之前我们先来简单了解一下websocket协议
WebSocket是一种在客户端和服务器之间建立长连接的技术,使得两者可以通过TCP套接字进行全双工通信。
通信的双方都可以同时发送和接收数据,而无需等待对方完成其操作。
其实现了浏览器与服务器全双工通信,能更好的节省服务器资源和带宽并达到实时通讯
WebSocket建立在 TCP 之上,同 HTTP 一样通过 TCP 来传输数据,但是它和 HTTP 最大不同是:
WebSocket 是一种双向通信协议,在建立连接后,WebSocket 服务器和 Browser/Client Agent 都能主动的向对方发送或接收数据
WebSocket 需要类似 TCP 的客户端和服务器端通过握手连接,连接成功后才能相互通信。
HTTP是一种无状态的请求/响应协议。它允许客户端从服务器获取资源,但是并不支持持久连接或双向通信。每次请求都需要重新建立TCP连接,因此对于频繁交互的应用来说效率较低。
关于 全双工通信和半双工通信
在通信系统中,双工是指同时进行的两个方向的数据传输。其中,全双工表示数据可以在两个方向同时传输,而半双工则指数据在同一时间只能在一个方向上传输。
场景的场景比如 : 电话对话和面对面交谈
demo
接下来我们通过 javax.websocket包来实现简单的demo , 更好理解websocket的工作流程以及方式
准备工作:
Postman : 充当 websocket 客户端
Springboot Application : 搭建websocket server
引入依赖
1234<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-websocket</artifactId></dependency>
示 ...
![Springboot+React集成第三方登录[适配器模式与桥接模式实践]](http://dhx-blog.oss-cn-beijing.aliyuncs.com/dhx/image-20231115122806823-17000226420621.png)
Springboot+React集成第三方登录[适配器模式与桥接模式实践]
最近在阅读 河北王校长 出版的 《贯穿设计模式》,刚好趁着这个机会给之前的BI项目扩展第三方登录
贯穿设计模式 : https://book.douban.com/subject/36579987/
这一章节 书中主要展示了以 适配器模式 以及 桥接模式 进行实践, 主要集成了 Gitee 的第三方登录
单从本章来讲(后面的还没有读完) , 阅读下来还是感觉非常友好的 , 作者对每一个要点都讲解的非常详细 , 并且配备了非常有趣的实际需求场景 , 非常适合像我这样不熟悉设计模式的小白去阅读
计划随着阅读进度对进行相应的实践 , 同时能扩展项目就更好了
本文主要结合作者的讲解 , 完整地实践通过适配器模式, 桥接模式 将原本的项目(BI Project)改造成为支持第三方登录。
完整前后端代码请参考
后端(Springboot): https://github.com/adorabled4/hxBI (不同的实现方式请查看对应的分支feature/3rdlogin-****)
前端(React + Antd Pro): https://github.com/adorabled4/hxBI-frontend
具体的三方登录的代码可通过最近的提交来查看 (日期: 2023年11月14日)
再此之前, 我们先从用户的角度 , 来看看第三方登录的流程
3rd登录流程
以CSDN为例
首先我们点击 前端的 icon (比如github)
接着会跳出 一个新的窗口
这里可以注意一下此页面的url
https://github.com/login/oauth/authorize?client_id=4bceac0b4d39cf045157&redirect_uri=https%3A%2F%2Fpassport.csdn.net%2Faccount%2Flogin%3FpcAuthType%3Dgithub%26newAuth%3Dtrue%26state%3Dtest
上面的参数有 :
client_id : 4bceac0b4d39cf045157
redirect_uri : https%3A%2F%2Fpassport.csdn.net%2Faccount%2Flogin%3FpcAuthType%3Dgithub%26newAuth ...
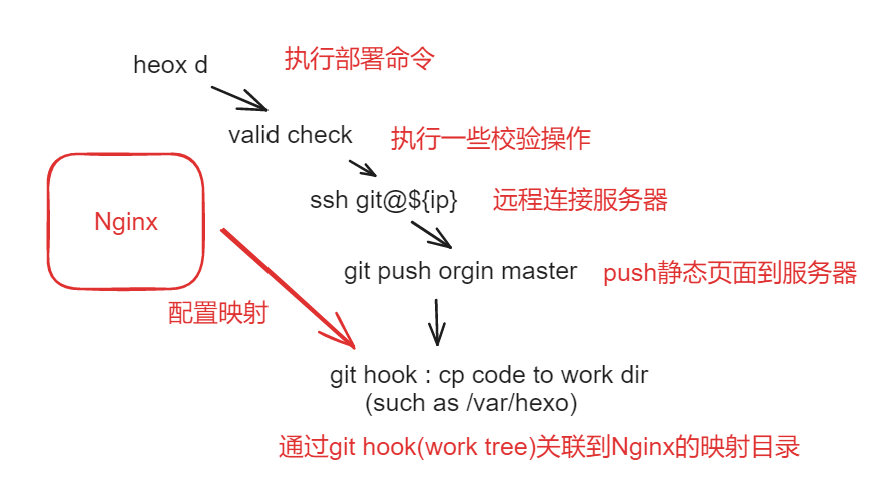
hexo-blog迁移工作(部署hexo到云服务器)
由于之前阿里云的服务器到期, 并且续费新的服务器很不友好 , 这里重新准备(白嫖)了一个新的服务器 , 因此需要迁移一下blog
准备工作
可以正确运行的blog(这里指的基本的配置没有问题 , 之前都可以正确运行)
云服务器(本文以centos 7.9为例)
core
准备服务器
这里准备一个全新的服务器, 意味着很多的东西都需要重新绑定, 配置, 因此搞起来还是有一点点麻烦的。
买服务器的话不需要多说, 只要是可以公网访问的Linux服务器都可以。
宝塔
虽然最开始学习Linux的时候很多人说不建议使用 xx面板 , 不过这里为了快速配置,还是用一下比较好233
如果你在选择服务器的时候已经选择了 宝塔面板 , 那么启动服务器输入bt 选择 14查看面板信息 , 公网登录即可
配置公钥
我们首先通过本地的shell工具远程连接服务器 (这里以Xshell为例)
登录的账户选择root , 密码可以在 服务器的控制台初始化用户密码
登录成功可以看到类似的 输出
123456Last login: Fri Nov 3 21:57:47 2023 from 122.206.190.75Welcome to Alibaba Cloud Elastic Compute Service ![root@iZbp1dul7chbryhj7h36btZ ~]#
添加用户
首先需要确定服务器安装 ssh 服务
这里我们添加用户 git 专门用来执行博客的上传操作
1useradd git
接着为git生成.ssh目录
12su gitssh-keygen
配置仓库
首先需要确定服务器安装了 Git 服务
12345678910[root@iZbp1dul7chbryhj7h36btZ ~]# git --versiongit version 1.8.3.1[root@iZbp1dul7chbryhj7h36btZ ~]# ps -ef | grep sshroot 1211 1 0 21:10 ? 00:00:00 /usr/sbin/sshd -Droot 14384 1211 0 21:39 ? 00:00:00 sshd: root@pts/0root 14881 1211 0 2 ...
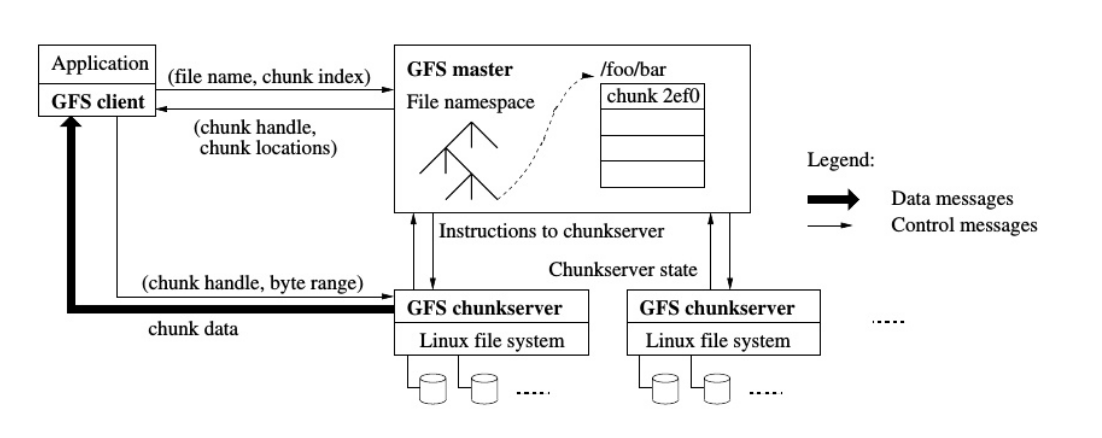
GFS(Google File System)论文解读
The Google file system 论文首次发布与2003年的SOSP会议上
关于SOSP
按照USnews的分类,Computer Science被分为四个大类:AI, Programming Language, Systems, Theory。毫无疑问,Systems是这四个大类中最要紧也是最大的一个。
SOSP是一个相对古老的会议,它是由ACM下属的SIGOPS (the ACM Special Interest Group on Operating Systems)于1967年创办的。会议两年一次,,每届收录的文章在20篇左右。
SOSP与OSDI是OS最好的会议,每两年开一次轮流开,比如今年是OSDI,那么明年就是SOSP。由于这两个会议方向很广,因此影响很大。
GFS主要解决的问题就是大型存储(分布式存储)的问题 。
在分布式系统中,可能有各种各样重要的抽象可以应用在分布式系统中,但实际上简单的存储接口往往非常有用且极其通用。
因此构建分布式系统大多都是关于如何设计存储系统,或是设计其它基于大型分布式存储的系统。
所以我们更加关注如何为大型分布式存储系统设计一个优秀的接口,以及如何设计存储系统的内部结构,这样系统才能良好运行。
Get Started
问题引入
设计分布式系统或者是大型存储系统的出发点往往是 获取更强的性能 。单台计算机的性能始终是有限的,通过利用多台计算机的资源来构建分布式系统可以来完成更多的工作。
例如目前服务器单台的硬盘容量能达到TB量级,但是数据的量级往往会更高,并且数据是在不断增长的。这里很容易就联想到把数据切分成多个切片(pieces) , 然后放到不同的计算机上面去存储,在读取的时候从多台计算机中去读取数据。
The largest cluster to date provides hun- dreds of terabytes of storage across thousands of disks on over a thousand machines, and it is concurrently accessed by hundreds of clients.
GFS由数百甚至数千台存储机器组成,这些存储机器由廉价的商品部件组装而成,并由大量的客户机访问。
在这些计算机中出现故障是非常常见的, 组件 ...

从Java字节码分析return与finally的执行流程
本篇注意探讨的问题是 finally与return代码哪个先执行?
先说结论 : 先执行return中的代码
执行顺序的问题 , 非常容易解决 , 请查看下面的代码
12345678910111213141516171819public static void main(String[] args) { System.out.printf("Int::main : %d\n",intVal);}static int add(){ int val = 0; try { val++; return returnInt(val); } finally { val++; System.out.printf("Int::finally : %d\n",val); }}static int returnInt(int val){ System.out.printf("Int::return : %d\n",val); return val;}
运行的结果是
123Int::return : 1Int::finally : 2Int::main : 1
执行顺序的问题解决了, 那么这里你可能会问 , 为什么 main中返回的结果是1呢?
还是先说结论,
由于Java中的参数传递只有值传递 , return的时候会先拷贝一个 val 的引用 , main函数中获取到的就是这个val的引用(对于基本数据类型是直接copy的)
这里我们可以查看反编译的代码
123456789101112131415161718static int add() { int val = 0; int var1; try { ++val; var1 = returnInt(val); } finally { ++val; System.out.printf("Int::finally : %d\n", val); } return var1;}static int returnInt(int val) { System.out.printf("Int::return : %d\n", val); ret ...