👉 day06 DFS/BFS
难度中等1854
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
DFS遍历 , 将走过的1 的网格标记为0
如果可以走通的话 , 维护cnt最后返回即可
每次dfs , 如果遇到了1 的格子, 那么一定是一个新的岛屿 , 因为前面走过的都是0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution { public int numIslands (char [][] grid) { int cnt=0 ; for (int i = 0 ; i < grid.length; i++) { for (int j = 0 ; j < grid[0 ].length; j++) { if (grid[i][j]=='1' ) cnt++; dfs(grid,i,j); } } return cnt; } void dfs (char [][]grid,int i,int j) { if (i<0 ||j<0 ||i>=grid.length|j>=grid[0 ].length||grid[i][j]=='0' ) return ; grid[i][j]='0' ; dfs(grid,i,j-1 ); dfs(grid,i,j+1 ); dfs(grid,i-1 ,j); dfs(grid,i+1 ,j); } }
难度中等853
有 n 个城市,其中一些彼此相连,另一些没有相连。如果城市 a 与城市 b 直接相连,且城市 b 与城市 c 直接相连,那么城市 a 与城市 c 间接相连。
省份 是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个 n x n 的矩阵 isConnected ,其中 isConnected[i][j] = 1 表示第 i 个城市和第 j 个城市直接相连,而 isConnected[i][j] = 0 表示二者不直接相连。
返回矩阵中 省份 的数量。
题意: n 个城市,有直接/间接相连关系的城市属于同一个省份,求省份的数量。
分析: 即 求无向图中的连通域的个数,入参int[][] isConnected即为该无向图的邻接矩阵。
常规做法可以对图进行深度优先搜索计数或使用广度优先搜索计数或者使用并查集。
思路:
我们使用图搜索算法从各个连通域的任一顶点开始遍历整个连通域,遍历的过程中对boolean[] visited数组进行标记,
遍历完当前连通域之后,若仍有顶点未被访问,说明又是一个新的连通域,使用 cnt 累计当前遍历过的连通域的数量。
DFS
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution { public int findCircleNum (int [][] isConnected) { int n = isConnected.length; boolean [] visited = new boolean [n]; int cnt = 0 ; for (int i = 0 ; i < n; i++) { if (!visited[i]) { cnt++; dfs(i, isConnected, visited); } } return cnt; } private void dfs (int i, int [][] isConnected, boolean [] visited) { visited[i] = true ; for (int j = 0 ; j < isConnected.length; j++) { if (isConnected[i][j] == 1 && !visited[j]) { dfs(j, isConnected, visited); } } }
并查集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Solution { public int findCircleNum (int [][] isConnected) { UnionFind uf= new UnionFind (isConnected.length); for (int i = 0 ; i < isConnected.length; i++) { for (int j = i+1 ; j < isConnected[i].length; j++) { if (isConnected[i][j]==1 ) uf.union(i,j); } } return uf.size.size(); } class UnionFind { public Map<Integer,Integer> parents=new HashMap <>(); public Map<Integer,Integer> size=new HashMap <>(); public UnionFind (int n) { for (int i = 0 ; i < n; i++) { parents.put(i,i); size.put(i,1 ); } } public int findFather (int p) { if (parents.get(p).equals(p)) return p; else return findFather(parents.get(p)); } public void union (int p,int q) { int phead=findFather(p); int qhead=findFather(q); if (phead==qhead) return ; int pSetSize=size.get(phead); int qSetSize=size.get(qhead); int small=pSetSize>=qSetSize?qhead:phead; int big=pSetSize<qSetSize?qhead:phead; parents.put(small,big); size.put(big,pSetSize+qSetSize); size.remove(small); } } }
DFS + BFS + 并查集,3 种方法计算无向图连通域数量 - 省份数量 - 力扣(LeetCode)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class Solution { public int findCircleNum (int [][] isConnected) { int n = isConnected.length; UnionFind uf = new UnionFind (n); for (int i = 0 ; i < n; i++) { for (int j = i + 1 ; j < n; j++) { if (isConnected[i][j] == 1 ) { uf.union(i, j); } } } return uf.size; } } class UnionFind { int [] roots; int size; public UnionFind (int n) { roots = new int [n]; for (int i = 0 ; i < n; i++) { roots[i] = i; } size = n; } public int find (int i) { if (i == roots[i]) { return i; } return roots[i] = find(roots[i]); } public void union (int p, int q) { int pRoot = find(p); int qRoot = find(q); if (pRoot != qRoot) { roots[pRoot] = qRoot; size--; } } }
🔔并查集
基本概念
并查集是一种数据结构
并查集这三个字,一个字代表一个意思。
并(Union),代表合并
查(Find),代表查找
集(Set),代表这是一个以字典为基础的数据结构,它的基本功能是合并集合中的元素,查找集合中的元素
并查集的典型应用是有关连通分量的问题
并查集解决单个问题(添加,合并,查找)的时间复杂度都是O(1)
因此,并查集可以应用到在线算法中
并查集的实现
并查集跟树有些类似,只不过她跟树是相反的。在树这个数据结构里面,每个节点会记录它的子节点。在并查集里,每个节点会记录它的父节点。
可以看到,如果节点是相互连通的(从一个节点可以到达另一个节点),
那么他们在同一棵树里,或者说在同一个集合里,或者说他们的祖先是相同的 。
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 public class UnionFindSet <V> { public HashMap<V, Element<V>> elementMap; public HashMap<Element<V>, Element<V>> fatherMap; public HashMap<Element<V>, Integer> rankMap; public UnionFindSet (List<V> list) { elementMap = new HashMap <>(); fatherMap = new HashMap <>(); rankMap = new HashMap <>(); for (V value : list) { Element<V> element = new Element <V>(value); elementMap.put(value, element); fatherMap.put(element, element); rankMap.put(element, 1 ); } } private Element<V> findHead (Element<V> element) { Stack<Element<V>> path = new Stack <>(); while (element != fatherMap.get(element)) { path.push(element); element = fatherMap.get(element); } while (!path.isEmpty()) { fatherMap.put(path.pop(), element); } return element; } public boolean isSameSet (V a, V b) { if (elementMap.containsKey(a) && elementMap.containsKey(b)) { return findHead(elementMap.get(a)) == findHead(elementMap.get(b)); } return false ; } public void union (V a, V b) { if (elementMap.containsKey(a) && elementMap.containsKey(b)) { Element<V> aF = findHead(elementMap.get(a)); Element<V> bF = findHead(elementMap.get(b)); if (aF != bF) { Element<V> big = rankMap.get(aF) >= rankMap.get(bF) ? aF : bF; Element<V> small = big == aF ? bF : aF; fatherMap.put(small, big); rankMap.put(big, rankMap.get(aF) + rankMap.get(bF)); rankMap.remove(small); } } } }
非泛型:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 public static class UnionFind { private HashMap<Node, Node> fatherMap; private HashMap<Node, Integer> rankMap; public UnionFind () { fatherMap = new HashMap <Node, Node>(); rankMap = new HashMap <Node, Integer>(); } private Node findFather (Node n) { Node father = fatherMap.get(n); if (father != n) { father = findFather(father); } fatherMap.put(n, father); return father; } public void makeSets (Collection<Node> nodes) { fatherMap.clear(); rankMap.clear(); for (Node node : nodes) { fatherMap.put(node, node); rankMap.put(node, 1 ); } } public boolean isSameSet (Node a, Node b) { return findFather(a) == findFather(b); } public void union (Node a, Node b) { if (a == null || b == null ) { return ; } Node aFather = findFather(a); Node bFather = findFather(b); if (aFather != bFather) { int aFrank = rankMap.get(aFather); int bFrank = rankMap.get(bFather); if (aFrank <= bFrank) { fatherMap.put(aFather, bFather); rankMap.put(bFather, aFrank + bFrank); } else { fatherMap.put(bFather, aFather); rankMap.put(aFather, aFrank + bFrank); } } } }
👉day 07 DFS/BFS
难度中等626
给定一个二叉树
1 2 3 4 5 6 struct Node { int val; Node *left; Node *right; Node *next; }
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
层序遍历(BFS ), 依次添加每一层 的节点, 然后更改节点的指向即可
定义pre 作为每一层的前一个节点, 用来存储当前节点的前一个节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution { public Node connect (Node root) { if (root==null ) return root; Queue<Node> que=new LinkedList <>(); que.add(root); while (que.size()!=0 ){ int size= que.size(); Node pre=new Node (-1 ); for (int i = 0 ; i < size; i++) { Node cur=que.poll(); pre.next=cur; if (cur.left!=null ) que.add(cur.left); if (cur.right!=null ) que.add(cur.right); pre=cur; } } return root; } }
更新pre最初定义为null
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution { public Node connect (Node root) { if (root==null ) return root; Queue<Node> que=new LinkedList <>(); que.add(root); while (que.size()!=0 ){ int size= que.size(); Node pre=null ; for (int i = 0 ; i < size; i++) { Node cur=que.poll(); if (pre!=null ) pre.next=cur; if (cur.left!=null ) que.add(cur.left); if (cur.right!=null ) que.add(cur.right); pre=cur; } } return root; } }
难度简单805
给你两棵二叉树 root 和 subRoot 。检验 root 中是否包含和 subRoot 具有相同结构和节点值的子树。如果存在,返回 true ;否则,返回 false 。
二叉树 tree 的一棵子树包括 tree 的某个节点和这个节点的所有后代节点。tree 也可以看做它自身的一棵子树。
BFS
层序遍历 , 当节点的val与目标子树的节点的val相同时 ,就判断两棵树是否相同
需要注意的是本题的root树的节点的val不唯一 ,因此需要额外的增加一个res , 用来存储判断结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution { public boolean isSubtree (TreeNode root, TreeNode subRoot) { boolean res=false ; Queue<TreeNode> queue=new LinkedList <>(); queue.add(root); while (queue.size()!=0 ){ if (res) return res; int size=queue.size(); for (int i=0 ;i<size;i++){ TreeNode tmp=queue.poll(); if (tmp.val==subRoot.val) res|=isMatch(tmp,subRoot); if (tmp.left!=null ) queue.add(tmp.left); if (tmp.right!=null ) queue.add(tmp.right); } } return res; } boolean isMatch (TreeNode r1,TreeNode r2) { if (r1==null &&r2==null ) return true ; if (r1==null ||r2==null ) return false ; return r1.val==r2.val&&isMatch(r1.left,r2.left)&&isMatch(r1.right,r2.right); } }
DFS
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution { public boolean isSubtree (TreeNode s, TreeNode t) { if (t == null ) return true ; if (s == null ) return false ; return isSubtree(s.left, t) || isSubtree(s.right, t) || isMatch(s,t); } public boolean isMatch (TreeNode r1, TreeNode r2) { if (r1==null &&r2==null ) return true ; if (r1==null ||r2==null ) return false ; return r1.val==r2.val&&isMatch(r1.left,r2.left)&&isMatch(r1.right,r2.right); } }
👉day 08 DFS/BFS
BFS最短路径问题(BFS,DFS的思考) - 二进制矩阵中的最短路径 - 力扣(LeetCode)
图论基础及遍历算法
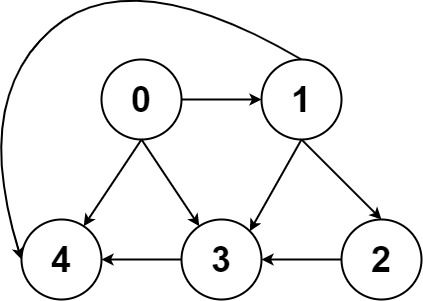
1️⃣图概述
一幅图是由节点 和边 构成的,逻辑结构如下:
什么叫「逻辑结构」?就是说为了方便研究,我们把图抽象成这个样子 。
根据这个逻辑结构,我们可以认为每个节点的实现如下:
1 2 3 4 5 class Vertex { int id; Vertex[] neighbors; }
它和我们之前说的多叉树节点几乎完全一样:
1 2 3 4 5 class TreeNode { int val; TreeNode[] children; }
2️⃣图的存储
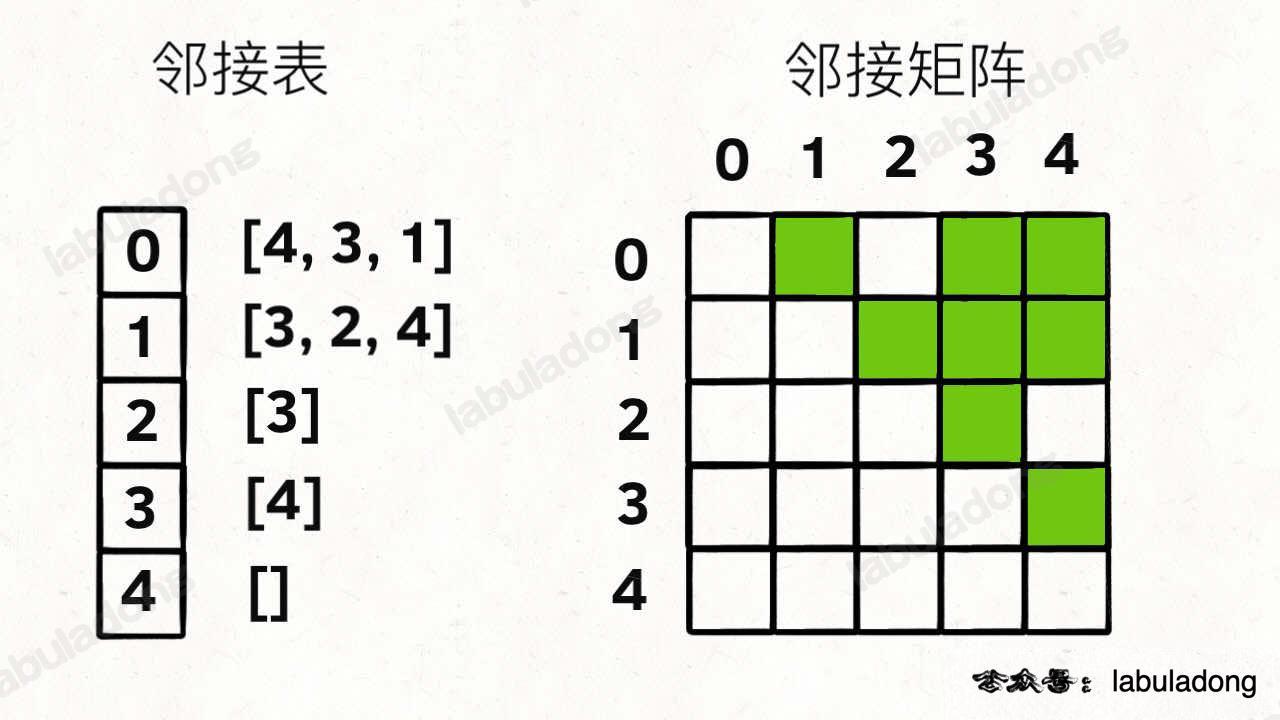
实际上我们很少用这个 Vertex 类实现图,而是用常说的邻接表和邻接矩阵 来实现。
用邻接表和邻接矩阵的存储方式如下:
邻接表很直观,我把每个节点 x 的邻居都存到一个列表里,然后把 x 和这个列表关联起来,这样就可以通过一个节点 x 找到它的所有相邻节点。
邻接矩阵则是一个二维布尔数组,我们权且称为 matrix,如果节点 x 和 y 是相连的,那么就把 matrix[x][y] 设为 true(上图中绿色的方格代表 true)。如果想找节点 x 的邻居,去扫一圈 matrix[x][..] 就行了。
如果用代码的形式来表现,邻接表和邻接矩阵大概长这样:
1 2 3 4 5 6 7 List<Integer>[] graph; boolean [][] matrix;
😄两种存储方式的对比
对于邻接表,好处是占用的空间少。
你看邻接矩阵里面空着那么多位置,肯定需要更多的存储空间。
但是,邻接表无法快速判断两个节点是否相邻。
比如说我想判断节点 1 是否和节点 3 相邻,我要去邻接表里 1 对应的邻居列表里查找 3 是否存在。但对于邻接矩阵就简单了,只要看看 matrix[1][3] 就知道了,效率高。
所以说,使用哪一种方式实现图,要看具体情况。
PS:在常规的算法题中,邻接表的使用会更频繁一些,主要是因为操作起来较为简单,但这不意味着邻接矩阵应该被轻视。矩阵是一个强有力的数学工具,图的一些隐晦性质可以借助精妙的矩阵运算展现出来。不过本文不准备引入数学内容,所以有兴趣的读者可以自行搜索学习。
最后,我们再明确一个图论中特有的度 (degree)的概念,在无向图中,「度」就是每个节点相连的边的条数。
由于有向图的边有方向,所以有向图中每个节点「度」被细分为入度 (indegree)和出度 (outdegree),比如下图:
其中节点 3 的入度为 3(有三条边指向它),出度为 1(它有 1 条边指向别的节点)。
好了,对于「图」这种数据结构,能看懂上面这些就绰绰够用了。
那你可能会问,我们上面说的这个图的模型仅仅是「有向无权图」,不是还有什么加权图,无向图,等等……
其实,这些更复杂的模型都是基于这个最简单的图衍生出来的 。
有向加权图怎么实现 ?
如果是邻接表,我们不仅仅存储某个节点 x 的所有邻居节点,还存储 x 到每个邻居的权重,不就实现加权有向图了吗?
如果是邻接矩阵,matrix[x][y] 不再是布尔值,而是一个 int 值,0 表示没有连接,其他值表示权重,不就变成加权有向图了吗?
如果用代码的形式来表现,大概长这样:
1 2 3 4 5 6 7 List<int []>[] graph; int [][] matrix;
无向图怎么实现 ?也很简单,所谓的「无向」,等同于「双向」
如果连接无向图中的节点 x 和 y,把 matrix[x][y] 和 matrix[y][x] 都变成 true 不就行了;邻接表也是类似的操作,在 x 的邻居列表里添加 y,同时在 y 的邻居列表里添加 x。
3️⃣图的遍历
各种数据结构被发明出来无非就是为了遍历和访问,所以「遍历」是所有数据结构的基础 。
图怎么遍历?还是那句话,参考多叉树,多叉树的 DFS 遍历框架如下:
1 2 3 4 5 6 7 8 9 void traverse (TreeNode root) { if (root == null ) return ; for (TreeNode child : root.children) { traverse(child); } }
图和多叉树最大的区别是,图是可能包含环的,你从图的某一个节点开始遍历,有可能走了一圈又回到这个节点,而树不会出现这种情况,从某个节点出发必然走到叶子节点,绝不可能回到它自身。
所以,如果图包含环,遍历框架就要一个 visited 数组进行辅助:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 boolean [] visited;boolean [] onPath;void traverse (Graph graph, int s) { if (visited[s]) return ; visited[s] = true ; onPath[s] = true ; for (int neighbor : graph.neighbors(s)) { traverse(graph, neighbor); } onPath[s] = false ; }
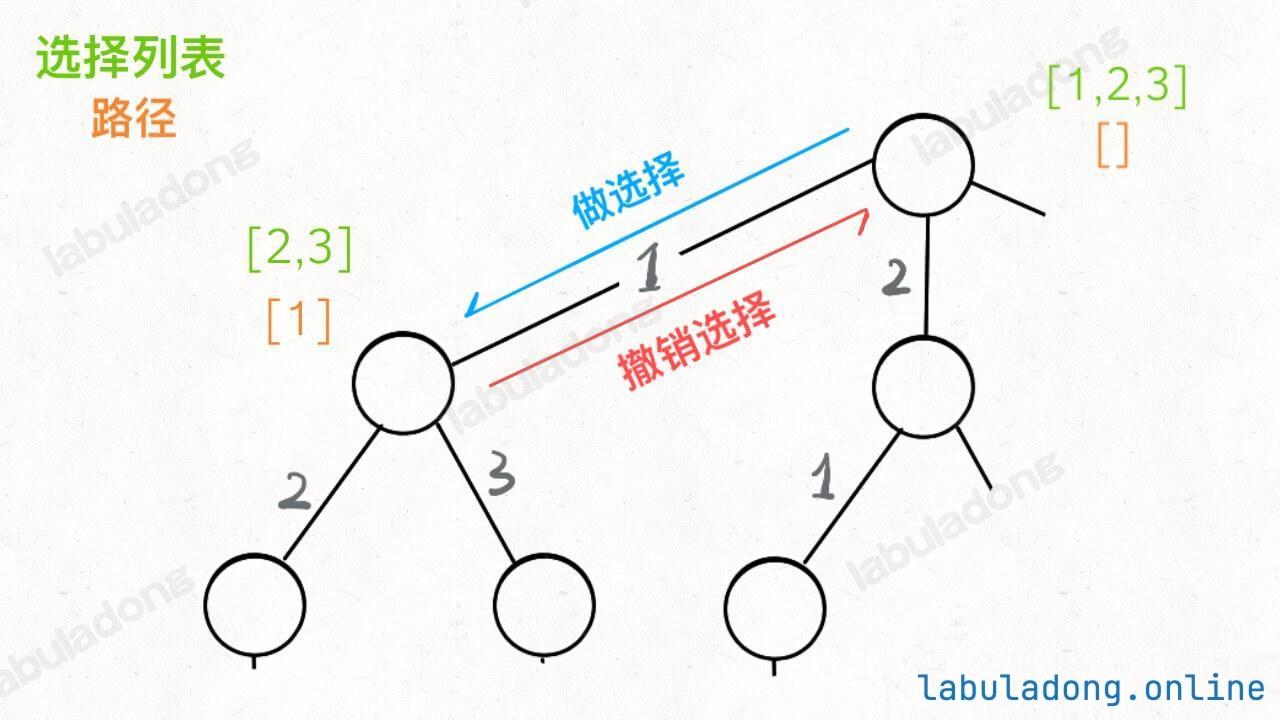
注意 visited 数组和 onPath 数组的区别,因为二叉树算是特殊的图,所以用遍历二叉树的过程来理解下这两个数组的区别:
上述 GIF 描述了递归遍历二叉树的过程,在 visited 中被标记为 true 的节点用灰色表示,在 onPath 中被标记为 true 的节点用绿色表示 ,类比贪吃蛇游戏,visited 记录蛇经过过的格子,而 onPath 仅仅记录蛇身。在图的遍历过程中,onPath 用于判断是否成环,类比当贪吃蛇自己咬到自己(成环)的场景,这下你可以理解它们二者的区别了吧。
如果让你处理路径相关的问题,这个 onPath 变量是肯定会被用到的,比如 拓扑排序 中就有运用。
另外,你应该注意到了,这个 onPath 数组的操作很像前文 回溯算法核心套路 中做「做选择」和「撤销选择」,区别在于位置:回溯算法的「做选择」和「撤销选择」在 for 循环里面,而对 onPath 数组的操作在 for 循环外面。
为什么有这个区别呢?
**回溯关注的不是节点,而是树枝。**不信你看前文画的回溯树,我们需要在「树枝」上做选择和撤销选择:
他们的区别可以这样反应到代码上:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void traverse (TreeNode root) { if (root == null ) return ; printf("进入节点 %s" , root); for (TreeNode child : root.children) { traverse(child); } printf("离开节点 %s" , root); } void backtrack (TreeNode root) { if (root == null ) return ; for (TreeNode child : root.children) { printf("从 %s 到 %s" , root, child); backtrack(child); printf("从 %s 到 %s" , child, root); } }
如果执行这段代码,你会发现根节点被漏掉了:
1 2 3 4 5 6 7 8 void traverse (TreeNode root) { if (root == null ) return ; for (TreeNode child : root.children) { printf("进入节点 %s" , child); traverse(child); printf("离开节点 %s" , child); } }
所以对于这里「图」的遍历,我们应该用 DFS 算法,即把 onPath 的操作放到 for 循环外面,否则会漏掉记录起始点的遍历。
说了这么多 onPath 数组,再说下 visited 数组,其目的很明显了,由于图可能含有环,visited 数组就是防止递归重复遍历同一个节点进入死循环的。
当然,如果题目告诉你图中不含环,可以把 visited 数组都省掉,基本就是多叉树的遍历。
难度中等218
给你一个 n x n 的二进制矩阵 grid 中,返回矩阵中最短 畅通路径 的长度。如果不存在这样的路径,返回 -1 。
二进制矩阵中的 畅通路径 是一条从 左上角 单元格(即,(0, 0))到 右下角 单元格(即,(n - 1, n - 1))的路径,该路径同时满足下述要求:
路径途经的所有单元格都的值都是 0 。
路径中所有相邻的单元格应当在 8 个方向之一 上连通(即,相邻两单元之间彼此不同且共享一条边或者一个角)。
畅通路径的长度 是该路径途经的单元格总数。
一般这种找最短路径, 最少次数的题目, 都是BFS
BFS
每个节点每次可以向8个方向前进
1 {{0 ,1 },{0 ,-1 },{1 ,0 },{-1 ,0 },{-1 ,-1 },{-1 ,1 },{1 ,-1 },{1 ,1 }}
前进的条件是
成功的条件为遍历到右下角位置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution { int [][] dirs = {{1 , 0 }, {-1 , 0 }, {0 , 1 }, {0 , -1 }, {1 , 1 }, {1 , -1 }, {-1 , 1 }, {-1 , -1 }}; boolean [][]vis; public int shortestPathBinaryMatrix (int [][] grid) { int path=1 ; int n= grid.length; vis=new boolean [n][n]; if (grid.length == 0 || grid[0 ].length == 0 || grid[0 ][0 ] == 1 || grid[n - 1 ][n - 1 ] == 1 ) return -1 ; Queue<int []> queue=new LinkedList <>(); queue.add(new int []{0 ,0 }); while (queue.size()!=0 ){ int size=queue.size(); for (int i = 0 ; i < size; i++) { int []tmp=queue.poll(); int x=tmp[0 ],y=tmp[1 ]; for (int [] d : dirs) { int nx=x+d[0 ]; int ny=y+d[1 ]; if (nx>=0 &&ny>=0 &&nx<n&&ny<n&&grid[nx][ny]==0 &&!vis[nx][ny]){ queue.add(new int []{nx,ny}); vis[nx][ny]=true ; } } if (x==n-1 &&y==n-1 ) return path; } path++; } return -1 ; } }
难度中等855
给你一个 m x n 的矩阵 board ,由若干字符 'X' 和 'O' ,找到所有被 'X' 围绕的区域,并将这些区域里所有的 'O' 用 'X' 填充。
思路
题目中解释说被包围的区间不会存在于边界上,所以我们会想到边界上的 O 要特殊处理,
只要把边界上的 O 特殊处理了,那么剩下的 O 替换成 X 就可以了。问题转化为,如何寻找和边界联通的 OO,我们需要考虑如下情况。
从边开始搜索
从边界开始递归, 如果是与边界上的O联通的 O , 那么最终一定是不会变成X 的, 因此 只需要从边界递归, 遇到X就return ,
把所有的与边界联通的O全部标记为# , 最后再做统一的转换
将 #全部变为o ,
剩余的那一部分不与边界联通的O , 转换为X , 因为这一部分必定是被 X包裹的
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution { public void solve (char [][] board) { if (board == null || board.length == 0 ) return ; int m = board.length,n = board[0 ].length; for (int i = 0 ; i < m; i++) { for (int j = 0 ; j < n; j++) { boolean isEdge=i==0 ||j==n-1 ||i==m-1 ||j==0 ; if (isEdge&&board[i][j]=='O' ){ dfs(board,i,j); } } } for (int i = 0 ; i < m; i++) { for (int j = 0 ; j < n; j++) { if (board[i][j]=='O' ) board[i][j]='X' ; if (board[i][j]=='#' ) board[i][j]='O' ; } } } void dfs (char [][] board, int i, int j) { if (i<0 ||j<0 ||i>=board.length||j>=board[0 ].length||board[i][j]=='X' ||board[i][j]=='#' ) return ; board[i][j]='#' ; dfs(board,i+1 ,j); dfs(board,i-1 ,j); dfs(board,i,j+1 ); dfs(board,i,j-1 ); } }
难度中等322
给你一个有 n 个节点的 有向无环图(DAG) ,请你找出所有从节点 0 到节点 n-1 的路径并输出(不要求按特定顺序 )
graph[i] 是一个从节点 i 可以访问的所有节点的列表(即从节点 i 到节点 graph[i][j]存在一条有向边)。
话不多说, 图的DFS , 直接上代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution { List<List<Integer>> res = new LinkedList <>(); public List<List<Integer>> allPathsSourceTarget (int [][] graph) { traverse(graph,0 ,new LinkedList <>()); return res; } void traverse (int [][] graph, int s, LinkedList<Integer> path) { int n=graph.length; path.addLast(s); if (s==n-1 ){ res.add(new LinkedList <>(path)); path.removeLast(); return ; } for (int v : graph[s]) { traverse(graph,v,path); } path.removeLast(); } }
👈类似题目
难度中等1726
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
有效 二叉搜索树定义如下:
节点的左子树只包含 小于 当前节点的数。
节点的右子树只包含 大于 当前节点的数。
所有左子树和右子树自身必须也是二叉搜索树。
暴力解法
中序遍历, 存储每个节点的元素, 如果存在前面的节点的val大于等于后面的节点的val 就return false;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution { List<Integer> list=new ArrayList <>(); public boolean isValidBST (TreeNode root) { inOrder(root); for (int i = 0 ; i < list.size()-1 ; i++) { if (list.get(i)>=list.get(i+1 )){ return false ; } } return true ; } public void inOrder (TreeNode root) { if (root==null ) return ; inOrder(root.left); list.add(root.val); inOrder(root.right); } }
不存储元素的解法
中序遍历, 每次都存储前面的节点的val, 如果下一个需要遍历的节点的val大于前面的那个节点的val return false 即可
左中右遍历二叉搜索树 ,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution { long pre = Long.MIN_VALUE; public boolean isValidBST (TreeNode root) { if (root == null ) { return true ; } if (!isValidBST(root.left)) { return false ; } if (root.val <= pre) { return false ; } pre = root.val; return isValidBST(root.right); } }
思路
难度简单2077
给你一个二叉树的根节点 root , 检查它是否轴对称。
关键在于 比较
left.left == right.rightleft.right== right.left
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution { public boolean isSymmetric (TreeNode root) { if (root==null ) return true ; return dfs(root.left,root.right); } public boolean dfs (TreeNode left,TreeNode right) { boolean res=true ; if (left==null &&right==null ){ return true ; } if (right==null ||left==null ){ return false ; } if (left.val!=right.val) return false ; return dfs(left.left,right.right)&&dfs(right.left,left.right); } }
难度中等1280
给你二叉树的根结点 root ,请你将它展开为一个单链表:
展开后的单链表应该同样使用 TreeNode ,其中 right 子指针指向链表中下一个结点,而左子指针始终为 null 。
展开后的单链表应该与二叉树 先序遍历
注意 :
虽然题目说的顺序是要求先序遍历 , 但是这并不代表我们的做法一定是先序遍历, 不要局限住自己的思想
思路
从二叉树的右子树开始遍历,
遍历的顺序是右左根 , 我们假设5这个节点, 那么
flatten(root.right) 先进入 6 , 此时last为null , 我们通过last存储上一个遍历的节点, 此时last=6,那么直接跳到下一步(这一步没有操作)
flatten(root.left) 进入4 , 对于4 ,他应该连接的是上一个遍历的节点 4.right=last , 然后使 left置空 , last存储4
接着进入5 , 5.right=last , 然后left置空, 接着存储last=5
通过这样的操作,
原本的
接着我们重复同样的操作, 区别就是last 不同了, 别的操作是一样的
代码实现
1 2 3 4 5 6 7 8 9 10 11 class Solution { TreeNode last=null ; public void flatten (TreeNode root) { if (root==null ) return ; flatten(root.right); flatten(root.left); root.right=last; root.left=null ; last=root; } }
难度中等722
给定一个二叉树的 root ,返回 最长的路径的长度 ,这个路径中的 每个节点具有相同值 。 这条路径可以经过也可以不经过根节点。
两个节点之间的路径长度 由它们之间的边数表示。
设计递归函数 int dfs(TreeNode root),含义为传入根节点 root,
返回以该节点为起点,往下走同值路径所能经过的最大路径长度(即不能同时往左右节点走 ),同时使用全局变量 max 记录答案路径所能经过最大路径长度。
在递归函数内部,先通过递归 root 的左右子节点,拿到以 root.left 和 root.right 为起点的最大路径长度 l 和 r,
然后根据当前节点值和左右子节点值的相等关系来更新 ans,
同时用 cur 维护**「以当前节点 root 为目标路径中深度最小(位置最高)节点时」**所经过的最大路径长度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution { public int longestUnivaluePath (TreeNode root) { dfs(root); return max; } int max=0 ; int dfs (TreeNode root) { if (root==null ) return 0 ; int ans=0 ,cur=0 ,l=dfs(root.left),r=dfs(root.right); if (root.left!=null &&root.left.val==root.val){ ans=l+1 ;cur=l+1 ; } if (root.right!=null &&root.right.val==root.val){ ans=Math.max(ans,r+1 ); cur+=r+1 ; } max=Math.max(max,cur); return ans; } }
labuladong 题解 思路
难度简单1147
给定一棵二叉树,你需要计算它的直径长度。一棵二叉树的直径长度是任意两个结点路径长度中的最大值。这条路径可能穿过也可能不穿过根结点。
思路与上一题基本相似
首先遍历左右孩子,获取左右孩子的最大的直径,
那么对于当前的节点来说, 他的最大直径= 左右孩子直径之和
对于当前节点的父节点来说, 当前的节点作为左右孩子的直径是左右孩子的最大直径+1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution { int max=0 ; public int diameterOfBinaryTree (TreeNode root) { dfs(root); return max; } int dfs (TreeNode root) { if (root==null ) return 0 ; int cur,ans,l=dfs(root.left),r=dfs(root.right); cur=l+r; max=Math.max(cur,max); ans=Math.max(l,r); return ans+1 ; } }
思路
难度困难1710
路径 被定义为一条从树中任意节点出发,沿父节点-子节点连接,达到任意节点的序列。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。
路径和 是路径中各节点值的总和。
给你一个二叉树的根节点 root ,返回其 最大路径和 。
思路与前两题基本一致
需要注意的是本题的题意是至少要选一个节点,
即使根节点是负的, 也要选, 因此要初始化max尽量小
其次是遍历的过程中如果左右子树的最大路径和小于0 , 就不选了
体现在l=Math.max(dfs(root.left),0)
对于cur 以及ans的维护, 与前两题完全一致
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution { int max=-0x3f3f3f3f ; public int maxPathSum (TreeNode root) { dfs(root); return max; } int dfs (TreeNode root) { if (root==null ) return 0 ; int l=Math.max(dfs(root.left),0 ),r=Math.max(dfs(root.right),0 ),cur=0 ,ans=0 ; cur=l+r+root.val; ans=Math.max(l,r)+root.val; max=Math.max(cur,max); return ans; } }
😈注意点
在二维矩阵中搜索,什么时候用BFS,什么时候用DFS?
如果只是要找到某一个结果是否存在,那么DFS会更高效 。
因为DFS会首先把一种可能的情况尝试到底,才会回溯去尝试下一种情况,只要找到一种情况,就可以返回了。
但是BFS必须所有可能的情况同时尝试,在找到一种满足条件的结果的同时,也尝试了很多不必要的路径;
如果是要找所有可能结果中最短的,那么BFS回更高效 。
因为DFS是一种一种的尝试,在把所有可能情况尝试完之前,无法确定哪个是最短,所以DFS必须把所有情况都找一遍,才能确定最终答案(DFS的优化就是剪枝,不剪枝很容易超时)。
而BFS从一开始就是尝试所有情况,所以只要找到第一个达到的那个点,那就是最短的路径,可以直接返回了,其他情况都可以省略了,所以这种情况下,BFS更高效。
BFS解法中的visited为什么可以全局使用?
BFS是在尝试所有的可能路径,哪个最快到达终点,哪个就是最短。那么每一条路径走过的路不同, visited(也就是这条路径上走过的点)也应该不同,那么为什么visited可以全局使用呢?
因为我们要找的是最短路径,那么如果在此之前某个点已经在visited中,也就是说有其他路径在小于或等于当前步数的情况下,
到达过这个点,证明到达这个点的最短路径已经被找到。那么显然这个点没必要再尝试了,
因为即便去尝试了,最终的结果也不会是最短路径了,所以直接放弃这个点即可。










 变成了
变成了 ,
,







