//关注 @PutMapping("/{id}/{isFollow}") public Result follow(@PathVariable("id") Long followUserId, @PathVariable("isFollow") Boolean isFollow) { return followService.follow(followUserId, isFollow); } //取消关注 @GetMapping("/or/not/{id}") public Result isFollow(@PathVariable("id") Long followUserId) { return followService.isFollow(followUserId); }
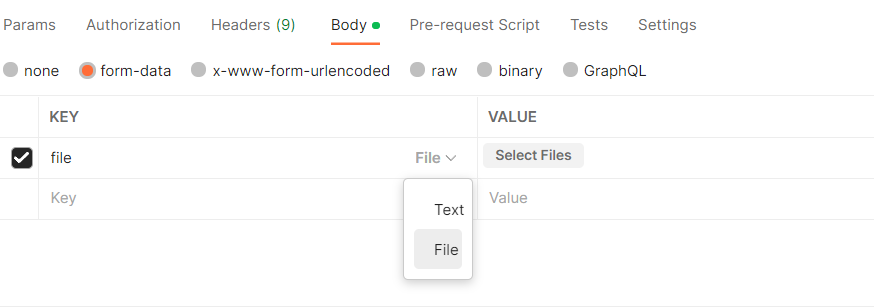
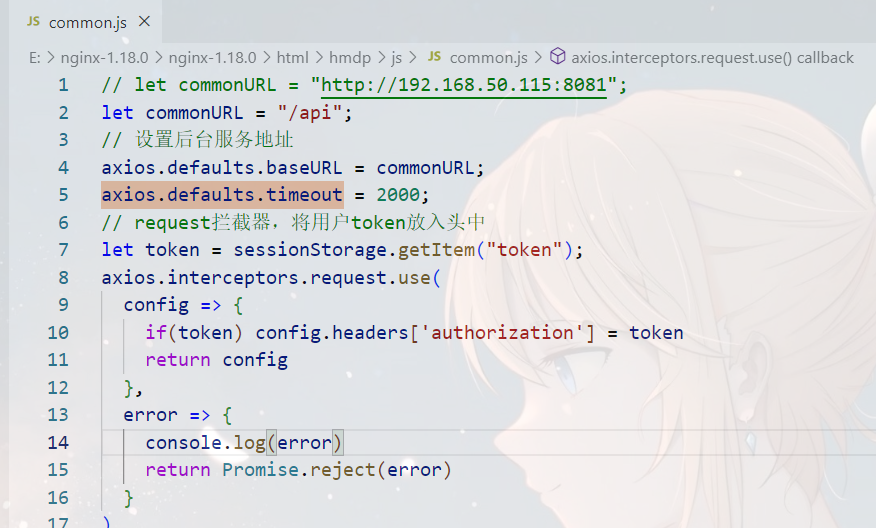
2022-10-14 19:30:29.969 ERROR 18236 --- [nio-8083-exec-6] com.hmdp.config.WebExceptionAdvice : org.springframework.web.multipart.MultipartException: Current request is not a multipart request
org.springframework.web.multipart.MultipartException: Current request is not a multipart request at org.springframework.web.method.annotation.RequestParamMethodArgumentResolver.handleMissingValue(RequestParamMethodArgumentResolver.java:196) ~[spring-web-5.2.15.RELEASE.jar:5.2.15.RELEASE] at org.springframework.web.method.annotation.AbstractNamedValueMethodArgumentResolver.resolveArgument(AbstractNamedValueMethodArgumentResolver.java:114) ~[spring-web-5.2.15.RELEASE.jar:5.2.15.RELEASE] at org.springframework.web.method.support.HandlerMethodArgumentResolverComposite.resolveArgument(HandlerMethodArgumentResolverComposite.java:121) ~[spring-web-5.2.15.RELEASE.jar:5.2.15.RELEASE] at org.springframework.web.method.support.InvocableHandlerMethod.getMethodArgumentValues(InvocableHandlerMethod.java:167) ~[spring-web-5.2.15.RELEASE.jar:5.2.15.RELEASE] at org.springframework.web.method.support.InvocableHandlerMethod.invokeForRequest(InvocableHandlerMethod.java:134) ~[spring-web-5.2.15.RELEASE.jar:5.2.15.RELEASE] at org.springframework.web.servlet.mvc.method.annotation.ServletInvocableHandlerMethod.invokeAndHandle(ServletInvocableHandlerMethod.java:105) ~[spring-webmvc-5.2.15.RELEASE.jar:5.2.15.RELEASE] at org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.invokeHandlerMethod(RequestMappingHandlerAdapter.java:878) ~[spring-webmvc-5.2.15.RELEASE.jar:5.2.15.RELEASE] at org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.handleInternal(RequestMappingHandlerAdapter.java:792) ~[spring-webmvc-5.2.15.RELEASE.jar:5.2.15.RELEASE] at org.springframework.web.servlet.mvc.method.AbstractHandlerMethodAdapter.handle(AbstractHandlerMethodAdapter.java:87) ~[spring-webmvc-5.2.15.RELEASE.jar:5.2.15.RELEASE] at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:1040) ~[spring-webmvc-5.2.15.RELEASE.jar:5.2.15.RELEASE] at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:943) ~[spring-webmvc-5.2.15.RELEASE.jar:5.2.15.RELEASE] at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:1006) ~[spring-webmvc-5.2.15.RELEASE.jar:5.2.15.RELEASE] at org.springframework.web.servlet.FrameworkServlet.doPost(FrameworkServlet.java:909) ~[spring-webmvc-5.2.15.RELEASE.jar:5.2.15.RELEASE] at javax.servlet.http.HttpServlet.service(HttpServlet.java:652) ~[tomcat-embed-core-9.0.46.jar:4.0.FR] at org.springframework.web.servlet.FrameworkServlet.service(FrameworkServlet.java:883) ~[spring-webmvc-5.2.15.RELEASE.jar:5.2.15.RELEASE] at javax.servlet.http.HttpServlet.service(HttpServlet.java:733) ~[tomcat-embed-core-9.0.46.jar:4.0.FR] at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:227) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:53) ~[tomcat-embed-websocket-9.0.46.jar:9.0.46] at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.springframework.web.filter.RequestContextFilter.doFilterInternal(RequestContextFilter.java:100) ~[spring-web-5.2.15.RELEASE.jar:5.2.15.RELEASE] at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119) ~[spring-web-5.2.15.RELEASE.jar:5.2.15.RELEASE] at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.springframework.web.filter.FormContentFilter.doFilterInternal(FormContentFilter.java:93) ~[spring-web-5.2.15.RELEASE.jar:5.2.15.RELEASE] at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119) ~[spring-web-5.2.15.RELEASE.jar:5.2.15.RELEASE] at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal(CharacterEncodingFilter.java:201) ~[spring-web-5.2.15.RELEASE.jar:5.2.15.RELEASE] at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119) ~[spring-web-5.2.15.RELEASE.jar:5.2.15.RELEASE] at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:202) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:97) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:542) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:143) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:92) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:78) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:357) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:374) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:65) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:893) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1707) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:49) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) ~[na:na] at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) ~[na:na] at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61) ~[tomcat-embed-core-9.0.46.jar:9.0.46] at java.base/java.lang.Thread.run(Thread.java:829) ~[na:na]

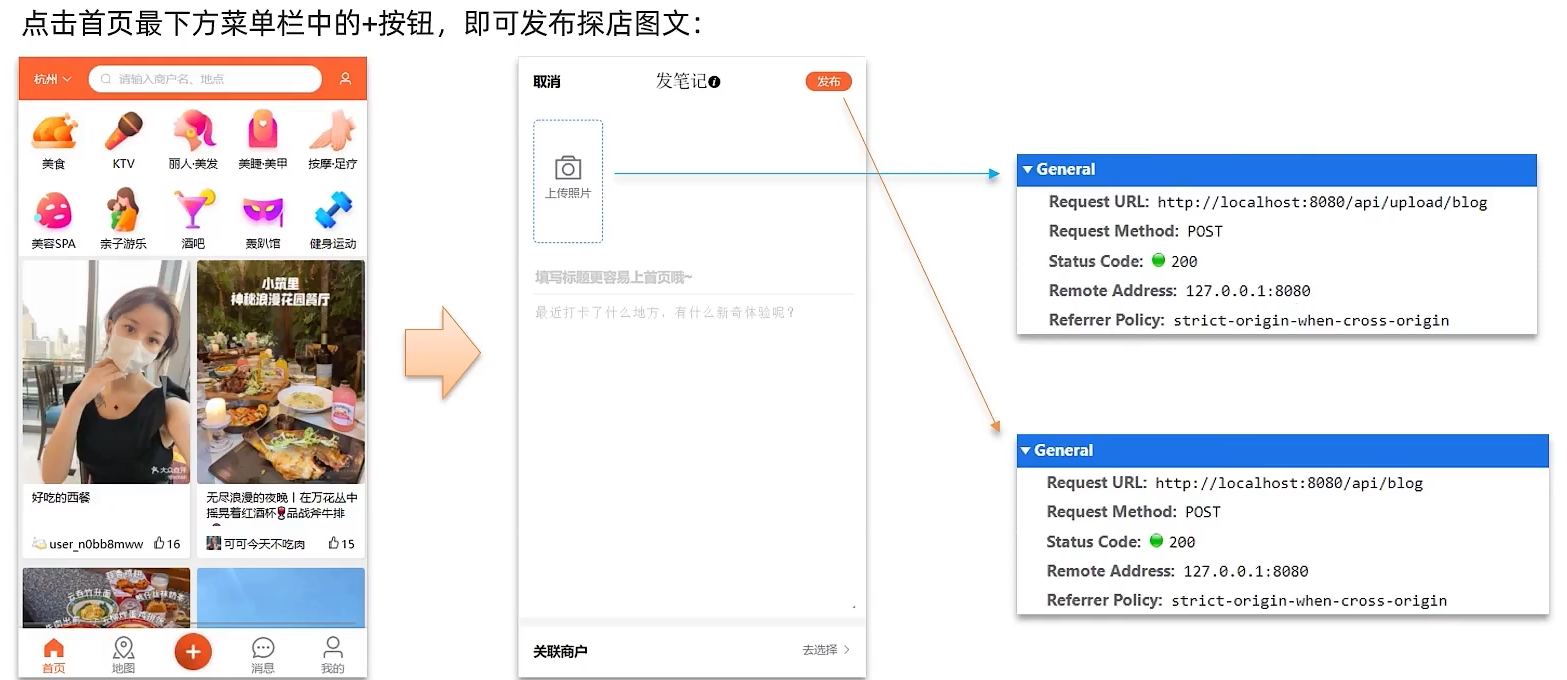
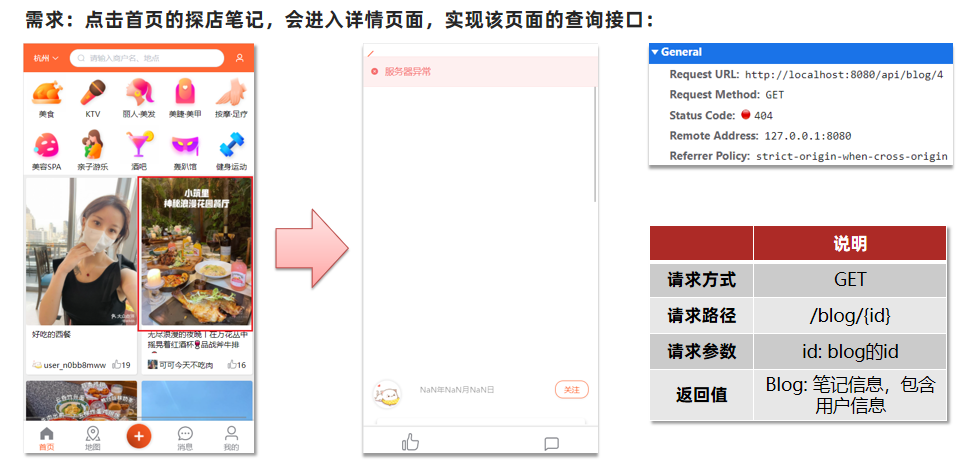

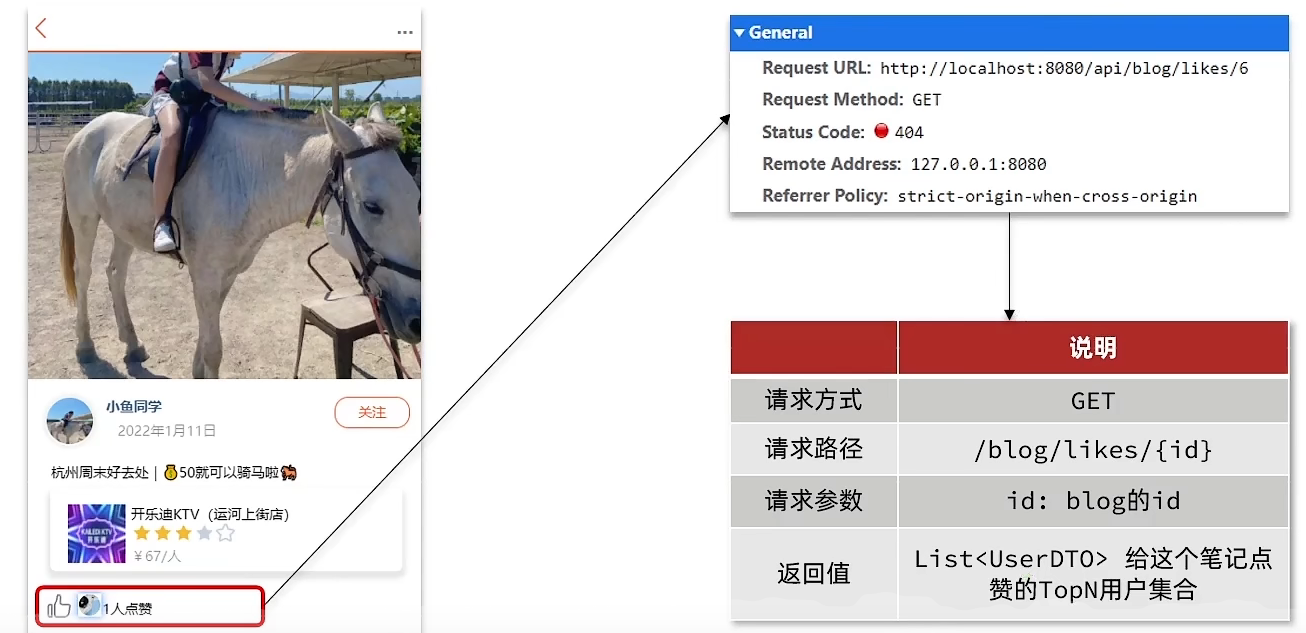

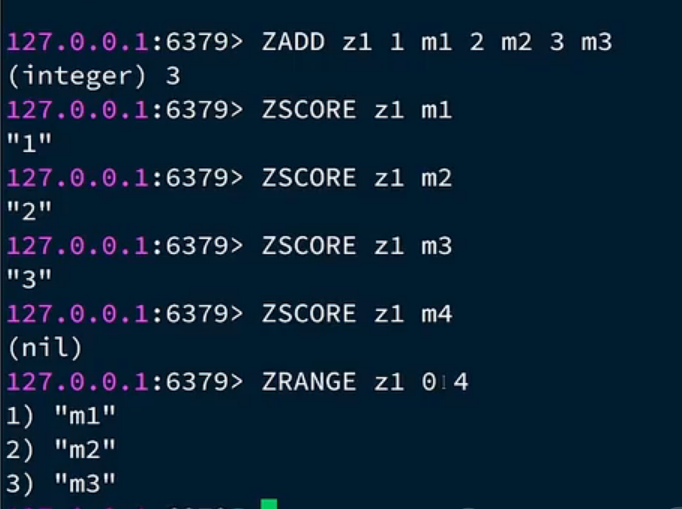


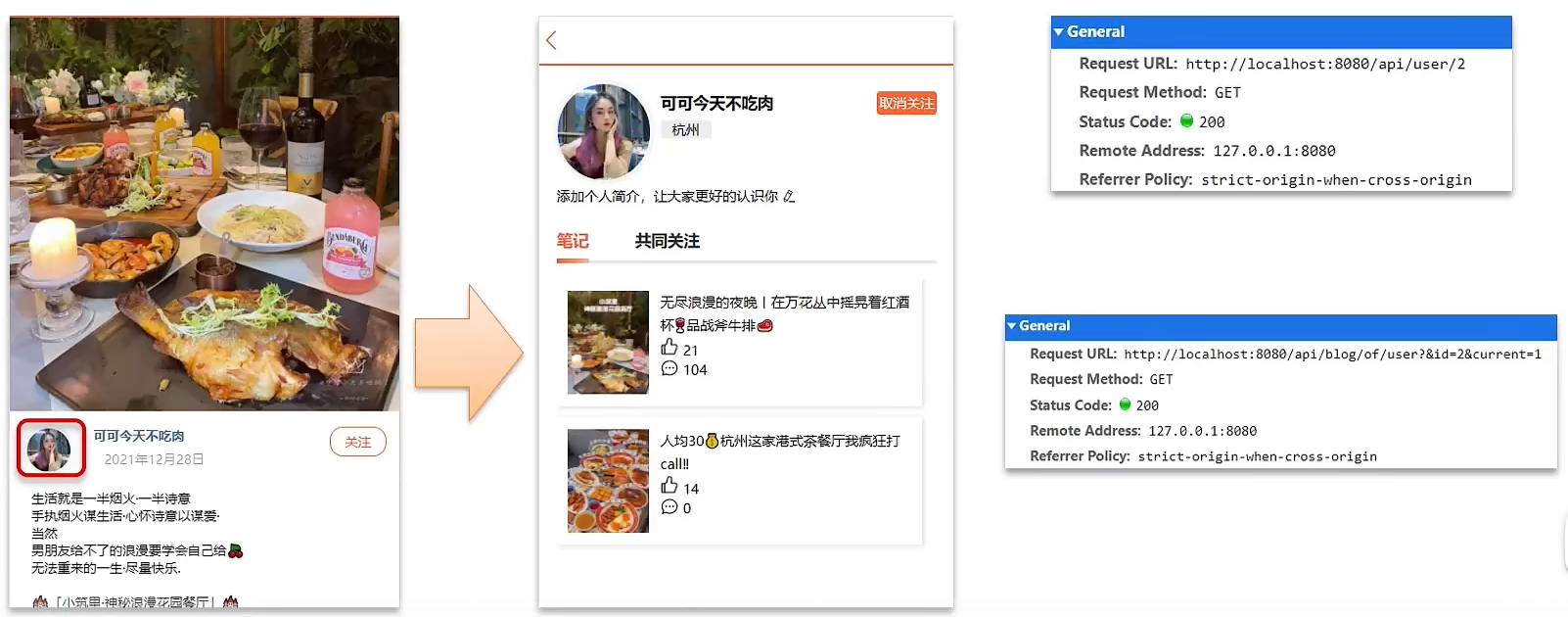




 会报错,
会报错,