
(四)文件系统[os]
4.1.1.文件管理
文件――就是一组有意义的信息/数据集合。
文件的属性
- 文件名: 由创建文件的用户决定文件名,主要是为了方便用户找到文件,同一目录下不允许有重名文件。
- 标识符: 一个系统内的各文件标识符唯一,对用户来说毫无可读性,因此标识符只是操作系统用于区分各个文件的一种内部名称。
- 类型: 指明文件的类型
- 位置: 文件存放的路径(让用户使用)、在外存中的地址(操作系统使用,对用户不可见)
- 大小: 指明文件大小创建时间、上次修改时间文件所有者信息
- 保护信息: 对文件进行保护的访问控制信息

文件分为有结构文件和无结构文件。
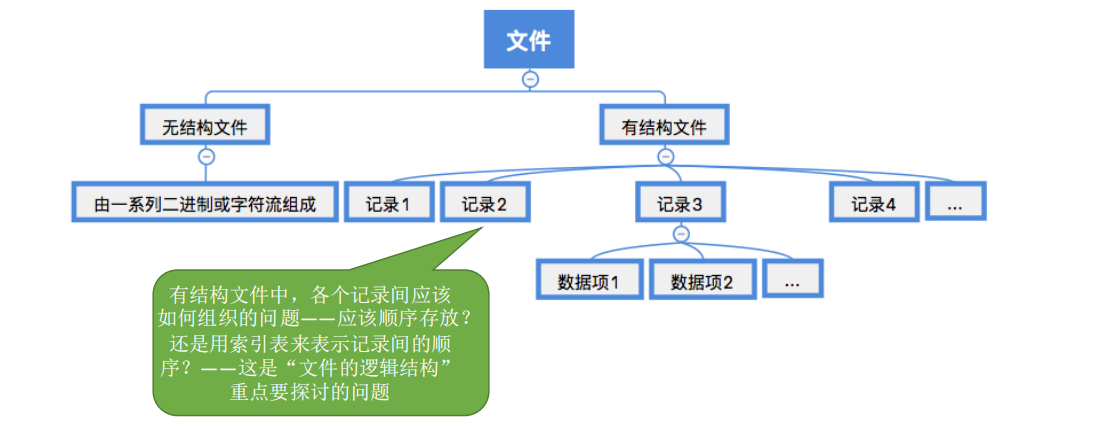
操作系统向上(用户和应用程序)提供的功能

4.1.2.文件的逻辑结构
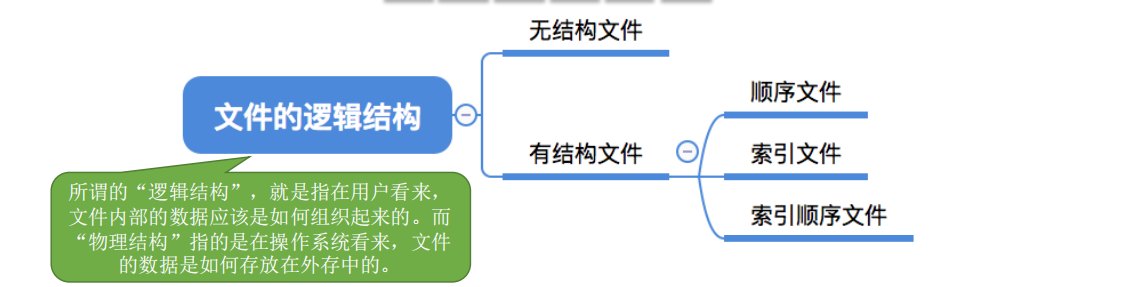
按文件是否有结构分类,可以分为无结构文件、有结构文件两种。
无结构文件:文件内部的数据就是一系列二进制流或字符流组成。又称“流式文件”。
- 如:Windows操作系统中的.txt文件。
⭐有结构文件:由一组相似的记录组成,又称“记录式文件”。每条记录又若干个数据项组成。如:数据库表文件。一般来说,每条记录有一个数据项可作为关键字(作为识别不同记录的ID)
我们主要研究有结构文件。

1.顺序文件
顺序文件:文件中的记录一个接一个地顺序排列(逻辑上),记录可以是定长的或可变长的。各个记录在物理上可以顺序存储(相当于数组)或链式存储(相当于链表)。
顺序存储又可以分为串结构和顺序结构。

那么这几种存储方式是否可以快速找到第i个记录对应的地址呢 ?

注:一般来说,考试题目中所说的“顺序文件”指的是物理上顺序存储的顺序文件。之后的讲解中提到的顺序文件也默认如此可见,顺序文件的缺点是增加/删除一个记录比较困难(如果是串结构则相对简单 , 因为不需要保证按照关键词顺序存储)
结论 : 定长记录的顺序文件,若物理上采用顺序存储,则可实现随机存取;若能再保证记录的顺序结构,则可实现快速检索(即根据关键字快速找到对应记录)
2.索引文件
思考:对于可变长记录文件,要找到第i个记录,必须先顺序第查找前i-1个记录, 但是很多应用场景中又必须使用可变长记录。如何解决这个问题?
这时我们可以建立一张索引表来快速找到第i个记录。如图所示:

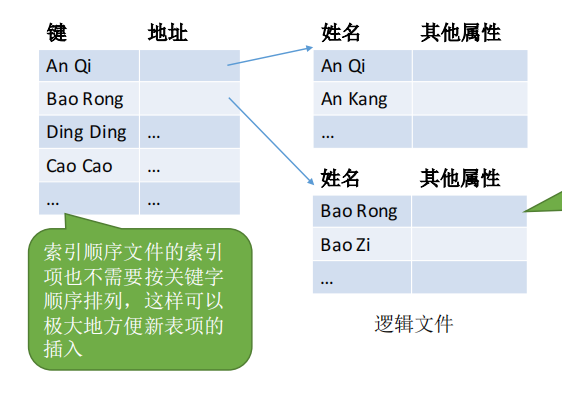
文件中的记录 可以 离散的存放, 但是索引表中的记录需要连续存放
索引表本身是定长记录的顺序文件。 因此可以快速找到第i个记录对应的索引项。
可将关键字作为索引号内容,若按关键字顺序排列,则还可以支持按照关键字折半查找。
每当要增加/删除一个记录时,需要对索引表进行修改。由于索引文件有很快的检索速度,因此主要用于对信息处理的及时性要求比较高的场合。
另外,可以用不同的数据项建立多个索引表。如:学生信息表中,可用关键字“学号”建立一张索引表。也可用“姓名”建立一张索引表。这样就可以根据“姓名”快速地检索文件了。(Eg: SQL就支持根据某个数据项建立索引的功能)
3.索引顺序文件
思考索引文件的缺点: 每个记录对应一个索引表项,因此索引表可能会很大。比如:文件的每个记录平均只占8字节,而每个索引表项占32个字节,那么索引表都要比文件内容本身大4倍,这样对存储空间的利用率就太低了。
那么如何解决呢?
我们可以建立一个索引顺序文件。
索引顺序文件是索引文件和顺序文件思想的结合。索引顺序文件中,同样会为文件建立一张索引表,但不同的是:并不是每个记录对应一个索引表项,而是一组记录对应一个索引表项。
在本例中,学生记录按照学生姓名的开头字母进行分组。每个分组就是一个顺序文件,分组内的记录不需要按关键字排序。
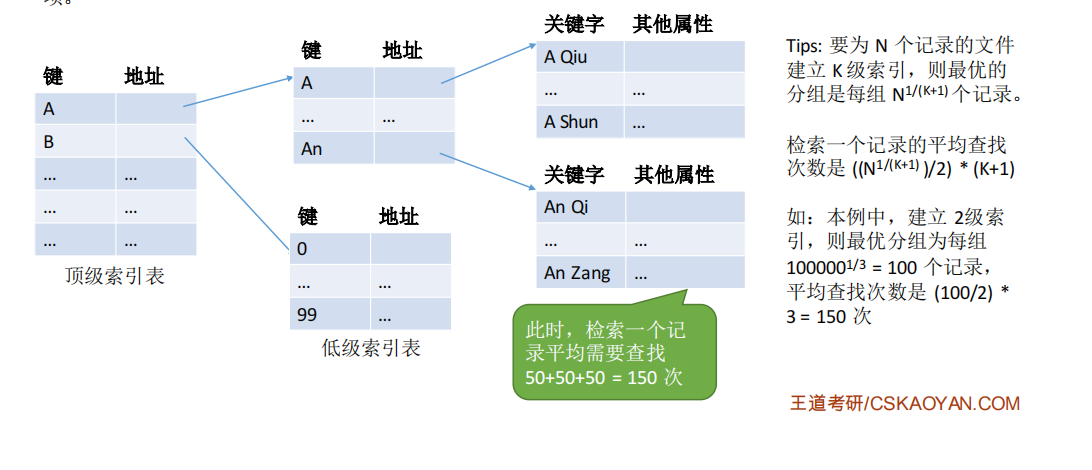
4.多级索引顺序文件
为了进一步提高检索效率,可以为顺序文件建立多级索引表。
例如,对于一个含10^6个记录的文件,可先为该文件建立一张低级索引表,每100个记录为一组,故低级索引表中共有10000个表项(即10000个定长记录),再把这10000个定长记录分组,每组100个,为其建立顶级索引表,故顶级索引表中共有100个表项。

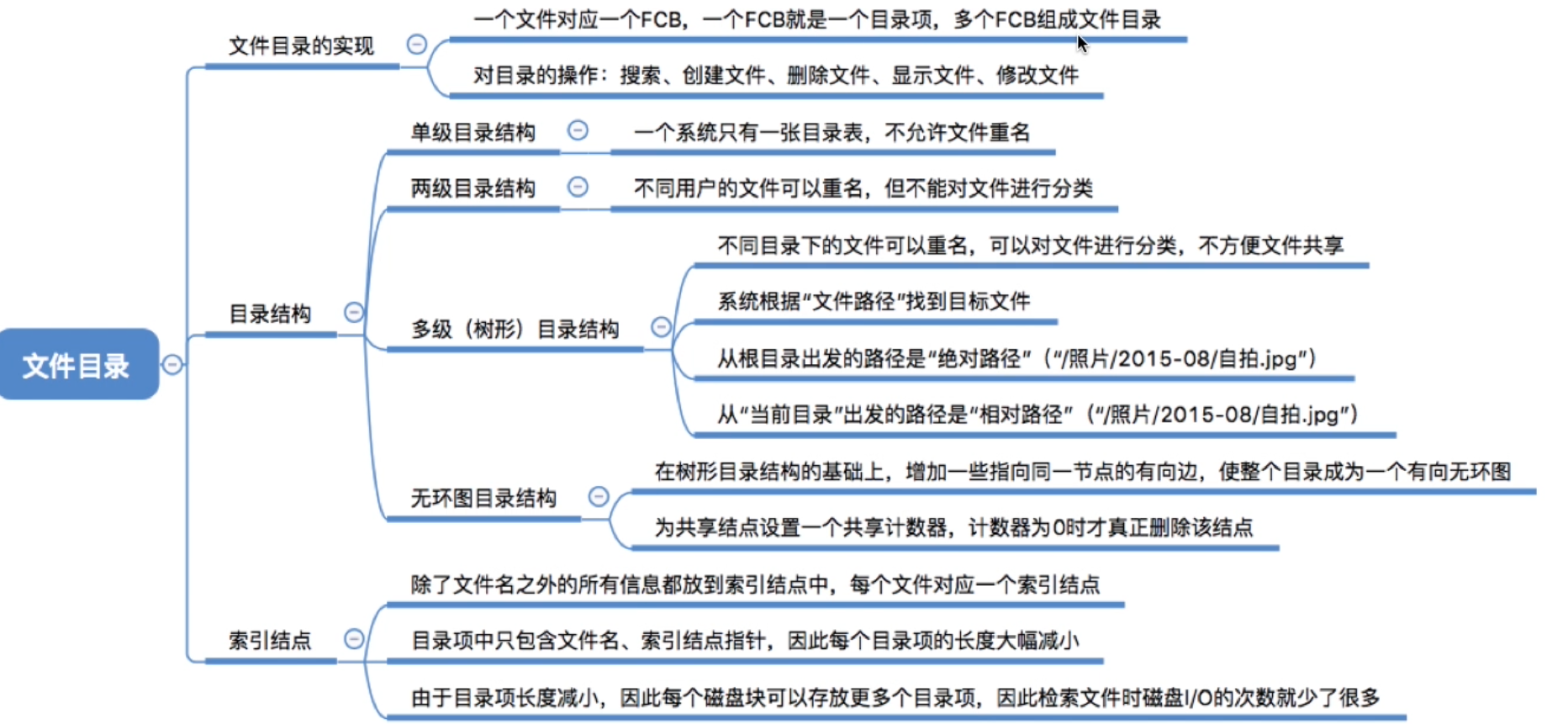
4.1.3.文件目录

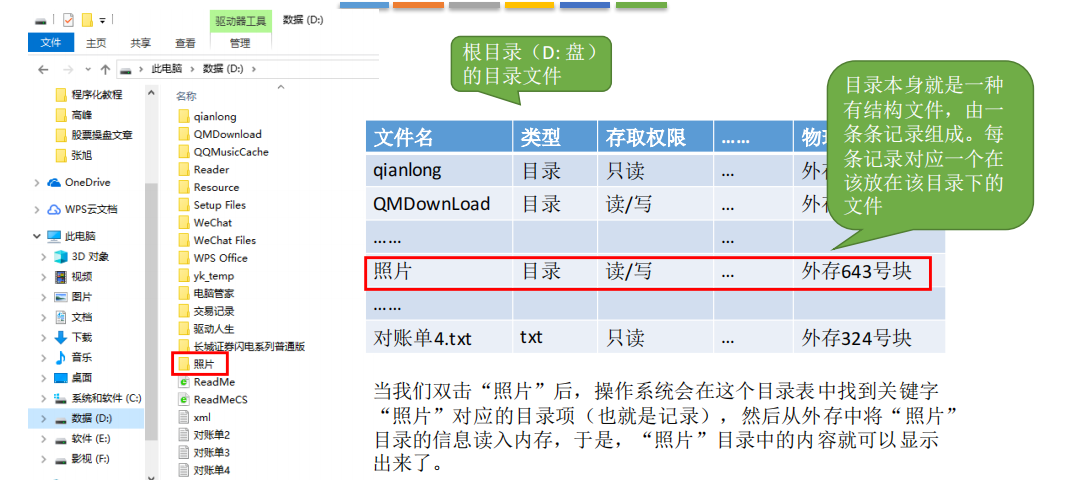
目录本身就是一种有结构文件,由一条条记录组成。每条记录对应一个放在该目录下的文件。如图所示
1.文件控制块(FCB)
- 目录文件中的一条记录就是一个 文件控制块(FCB , file control block)
PCB - 进程控制块
FCB的有序集合称为“文件目录”,一个FCB就是一个文件目录项。
FCB中包含了文件的基本信息(文件名、物理地址、逻辑结构、物理结构等),存取控制信息(是否可读/可写、禁止访问的用户名单等),使用信息(如文件的建立时间、修改时间等)。
最重要,最基本的还是文件名、文件存放的物理地址。
2.单级目录结构

3.二级目录结构
- 允许出现多用户 , 但是用户无法对文件进行分类

4.多级目录结构(树形目录结构)

树形目录结构可以很方便地对文件进行分类,层次结构清晰,也能够更有效地进行文件的管理和保护。
但是,树形结构不便于实现文件的共享。为此,提出了“无环图目录结构”。
相对路径
例如,此时己经打开了“照片”的目录文件,也就是说,这张目录表已调入内存,那么可以把它设置为
“当前目录”。当用户想要访问某个文件时,可以使用从当前目录出发的“相对路径”。
在Linux中,“.”表示当前目录,因此如果“照片”是当前目录,则”自拍.jpg”的相对路径为:
“./2015-08/自拍jpg”。从当前路径出发,只需要查询内存中的“照片”目录表,即可知道"2015-08”目录
表的存放位置,从外存调入该目录,即可知道“自拍jPg”存放的位置了。
5.无环图目录结构
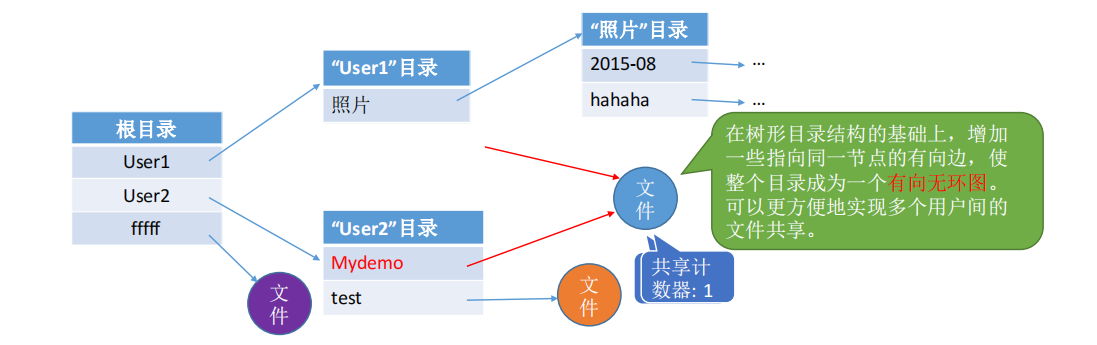
可以用不同的文件名指向同一个文件,甚至可以指向同一个目录(共享同一目录下的所有内容)。
需要为每个共享结点设置一个共享计数器,用于记录此时有多少个地方在共享该结点。
用户提出删除结点的请求时,只是删除该用户的FCB、并使共享计数器减1,并不会直接删除共享结点。
只有共享计数器减为0时,才删除结点。
注意: 共享文件不同于复制文件。在共享文件中,由于各用户指向的是同一个文件,因此只要其中一个用户修改了文件数据,那么所有用户都可以看到文件数据的变化。
6.索引结点(对FCB的改进)
- 简化结构 提高搜索效率 (在搜索文件的时候只需要 文件名)
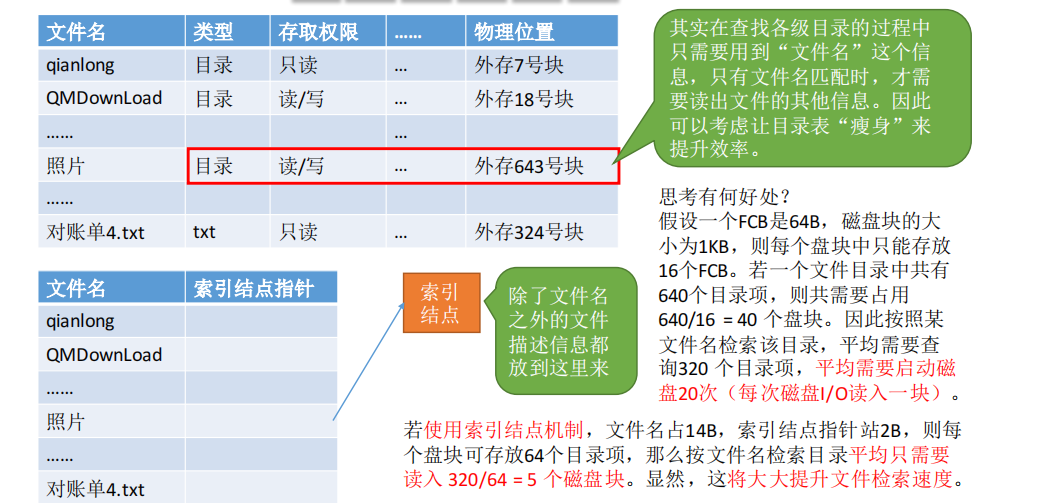
当找到文件名对应的目录项时,才需要将索引结点调入内存,索引结点中记录了文件的各种信息,包括文件在外存中的存放位置,根据“存放位置”即可找到文件。
存放在外存中的索引结点称为“磁盘索引结点”,当索引结点放入内存后称为“内存索引结点”。相比之下内存索引结点中需要增加一些信息,比如:文件是否被修改、此时有几个进程正在访问该文件等。
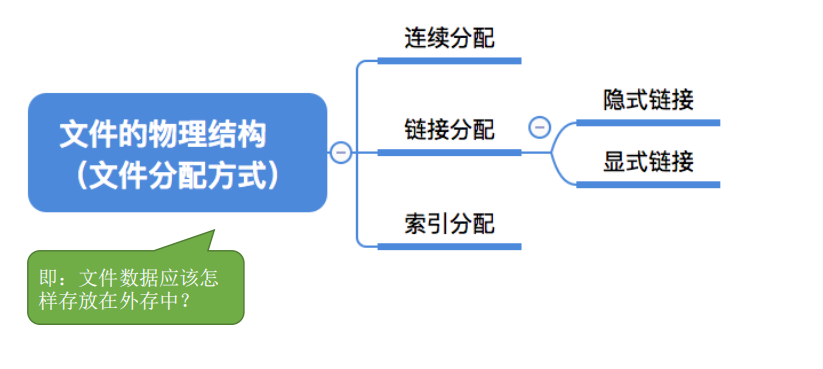
4.1.4.文件分配方式(文件物理结构)⭐
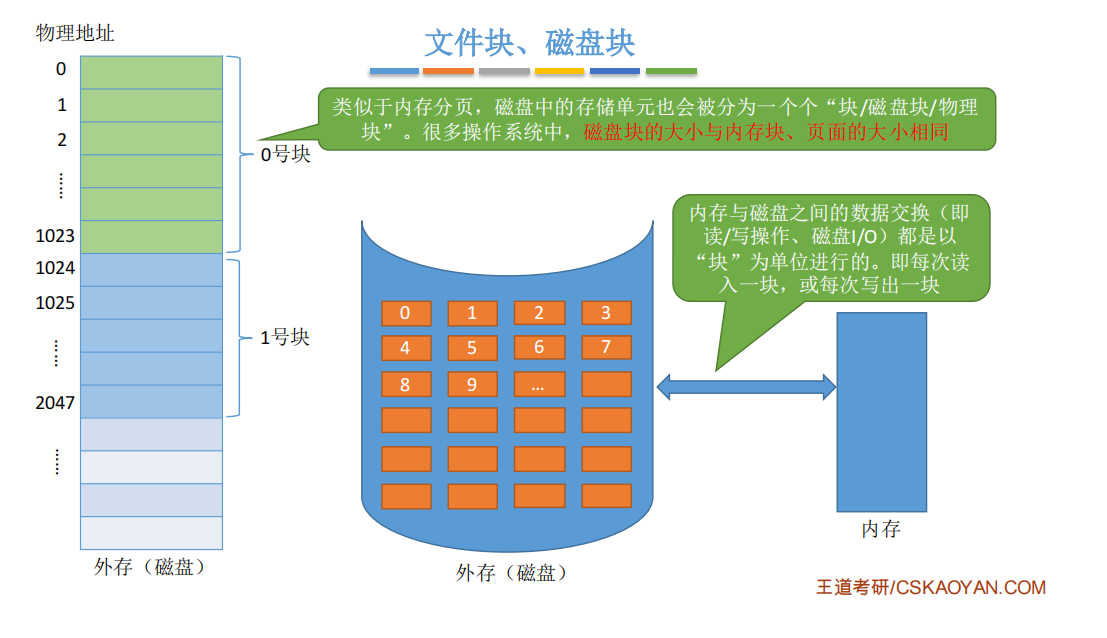
在介绍这些分配方式之前,先介绍一下什么是文件块,磁盘块。
很多操作系统中,磁盘块的大小与内存块、页面的大小相同 , 方便进行数据交换
在内存管理中,进程的逻辑地址空间被分为一个一个页面。
同样的,在外存管理中,为了方便对文件数据的管理,文件的逻辑地址空间也被分为了一个一个的文件“块”。
于是文件的逻辑地址也可以表示为(逻辑块号,块内地址)的形式。
用户通过逻辑地址来操作自己的文件,操作系统要负责实现从逻辑地址到物理地址的映射。
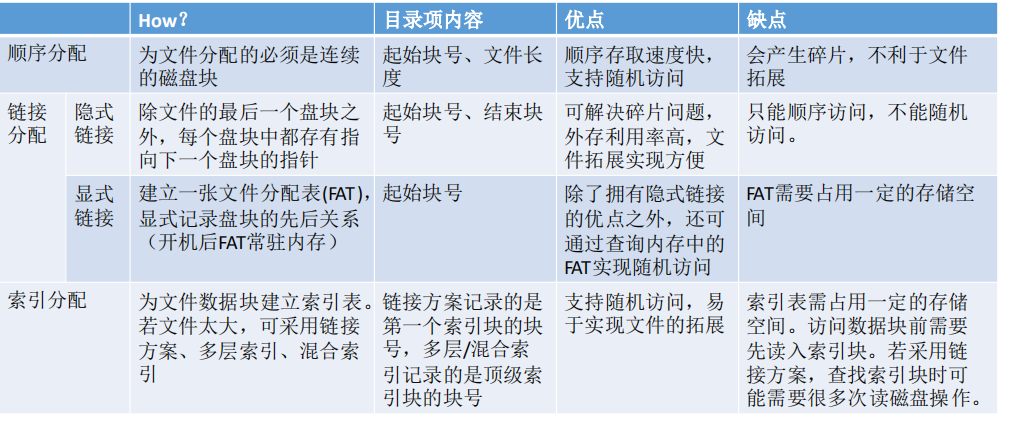
1.连续分配
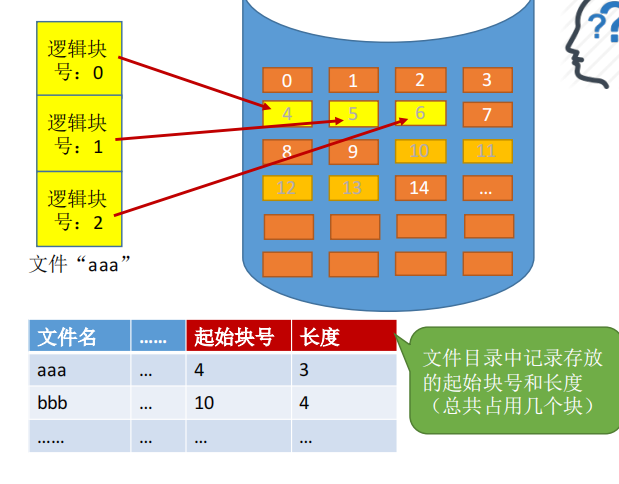
**连续分配方式要求每个文件在磁盘上占有一组连续的块。**如图所示
用户给出要访问的逻辑块号,操作系统找到该文件对应的目录项(FCB)
物理块号=起始块号+逻辑块号
当然,还需要检查用户提供的逻辑块号是否合法(逻辑块号≥长度就不合法)、
优点:
- 支持顺序访问和直接访问(即随机访问)
- 连续分配的文件在顺序访问时速度最快
访问速度与 磁头移动的速度有关, 连续分配 遇到相邻的块 只需要移动一次 磁头, 因此速度快
缺点:不方便文件拓展; 存储空间利用率低,会产生磁盘碎片
碎片较多
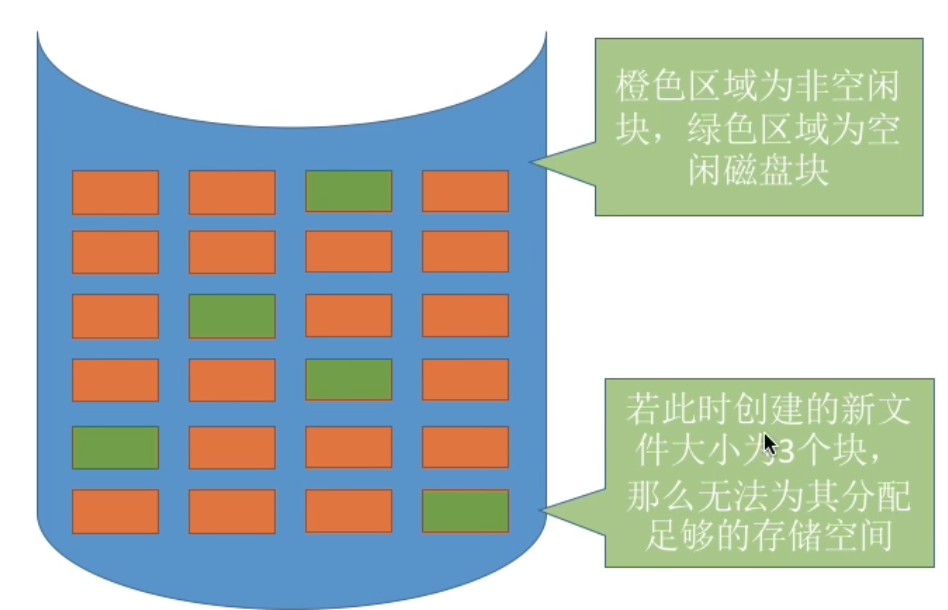
结论:物理上采用连续分配,存储空间利用率低,会产生难以利用的磁盘碎片 , 可以用紧凑来处理碎片,但是需要耗费很大的时间代价。
2.链接分配
隐式链接
链接分配采取离散分配的方式,可以为文件分配离散的磁盘块。分为隐式链接和显式链接两种。
- 从逻辑块号到物理块号的转变
用户给出要访问的逻辑块号i,操作系统找到该文件对应的目录项(FCB)
从目录项中找到起始块号(即0号块),将0号逻辑块读入内存,由此知道1号逻辑块存放的物理块号,于是读入1号逻辑块,再找到2号逻辑块的存放位置…以此类推。
因此,==读入i号逻辑块,总共需要i+1次磁盘l/O==。
结论:采用链式分配(隐式链接)方式的文件,只支持顺序访问,不支持随机访问,查找效率低。另外,指向下一个盘块的指针也需要耗费少量的存储空间。
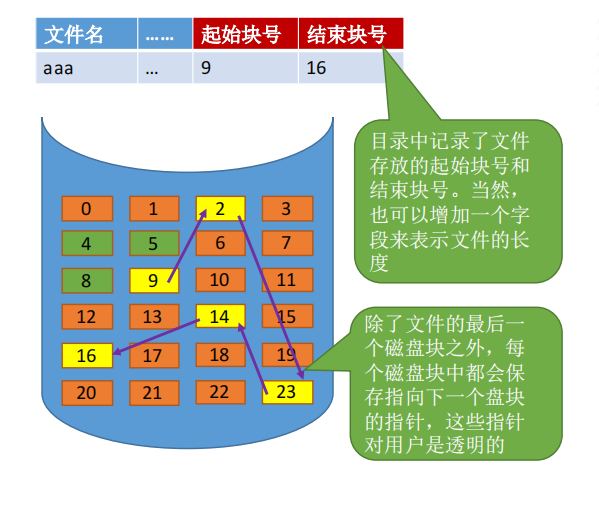
显式链接
把用于链接文件各物理块的指针显式地存放在一张表中。即==文件分配表==(FAT,File Allocation Table)。如图所示
- 从逻辑块号到物理块号的转变
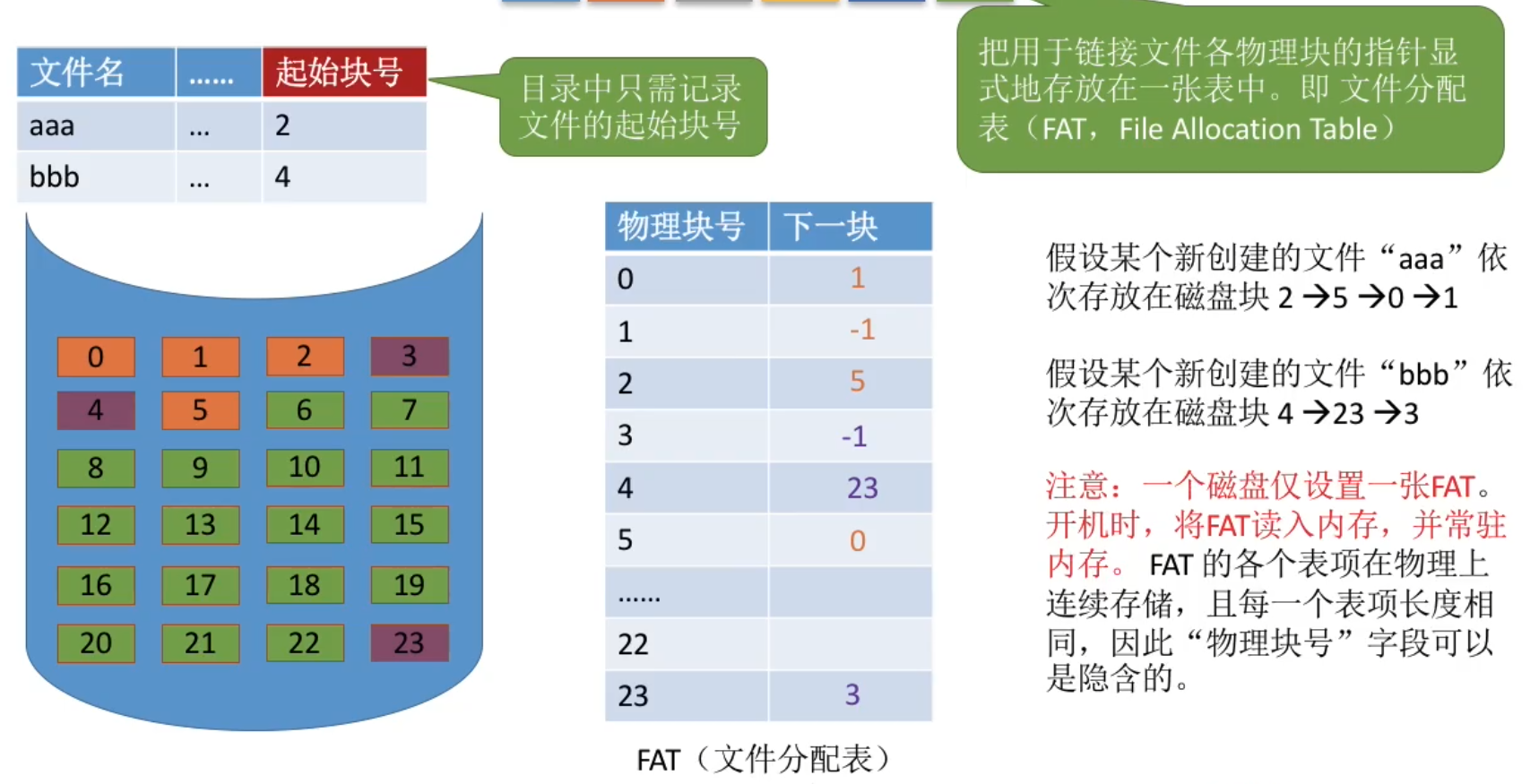
注意:一个磁盘仅设置一张FAT。 开机时,将FAT读入内存,并常驻内存。FAT的各个表项在物理上连续存储,且每一个表项长度相同,因此“物理块号”字段可以是隐含的。
用户给出要访问的逻辑块号i,操作系统找到该文件对应的目录项( FCB)
从目录项中找到起始块号,若i>0,则查询内存中的文件分配表FAT,往后找到i号逻辑块对应的物理块号。逻辑块号转换成物理块号的过程不需要读磁盘操作。
结论: 采用链式分配(显式链接)方式的文件,支持顺序访问,也支持随机访问(想访问i号逻辑块时,并不需要依次访问之前的 0~i-1号逻辑块),由于块号转换的过程不需要访问磁盘,因此相比于隐式链接来说,访问速度快很多。
显然,显式链接也不会产生外部碎片,也可以很方便地对文件进行拓展。
两种链接分配方式总结
隐式链接――除文件的最后一个盘块之外,每个盘块中都存有指向下一个盘块的指针。文件目录包括文件第一块的指针和最后一块的指针。
- 优点:很方便文件拓展,不会有碎片问题,外存利用率高。
- 缺点:只支持顺序访问,不支持随机访问,查找效率低,指向下一个盘块的指针也需要耗费少量的存储空间。
显式链接――把用于链接文件各物理块的指针显式地存放在一张表中,即文件分配表(FAT,FileAllocation Table)。一个磁盘只会建立一张文件分配表。开机时文件分配表放入内存,并常驻内存。
- 优点:很方便文件拓展,不会有碎片问题,外存利用率高,并且支持随机访问。相比于隐式链接来说,地址转换时不需要访问磁盘,因此文件的访问效率更高。
- 缺点:文件分配表的需要占用一定的存储空间。
3.索引分配
4.1_4_文件的物理结构(下)_哔哩哔哩_bilibili
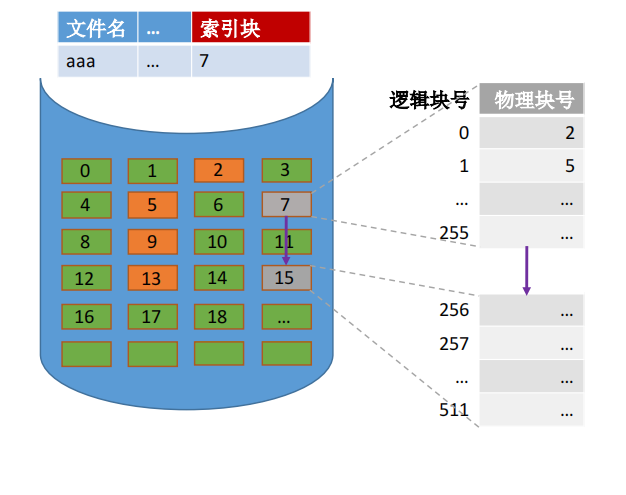
索引分配允许文件离散地分配在各个磁盘块中,系统会为每个文件建立一张索引表,索引表中记录了文件的各个逻辑块对应的物理块(索引表的功能类似于内存管理中的页表――建立逻辑页面到物理页之间的映射关系)。索引表存放的磁盘块称为索引块。文件数据存放的磁盘块称为数据块。
从逻辑块号到物理块号的转变
用户给出要访问的逻辑块号 i,操作系统找到该文件对应的目录项(FCB)
从目录项中可知索引表存放位置,将索引表从外存读入内存,并查找索引表即可知道i号逻辑块在外存中的存放位置。
可见,索引分配方式可以支持随机访问。文件拓展也很容易实现 (只需要给文件分配一个空闲块,并增加一个索引表项即可)
但是索引表需要占用一定的存储空间
注:
在显式链接的链式分配方式中,文件分配表FAT是一个磁盘对应一张。
而索引分配方式中,索引表是一个文件对应一张

文件过大的问题
如果一个文件的索引表太大,一个磁盘块放不下,那么如何解决呢?
可以用以下三种方式解决。
链接方案
如果索引表太大,一个索引块装不下,那么可以将多个索引块链接起来存放。
链接方案显然比较低效
假设磁盘块大小为1KB,一个索引表项占4B,则一个磁盘块只能存放256
个索引项若一个文件大小为256* 256KB=65,536KB=64MB
该文件共有256 * 256个块,也就对应256*256个索引项,也就需要256个索引块来存储,这些索引块用链接方案连起来。
若想要访问文件的最后一个逻辑块,就必须找到最后一余索引块(第256个索引块),而各个索引块之间是用指针链接起来的,因此必须先顺序地读入前255个索引块。
多层索引
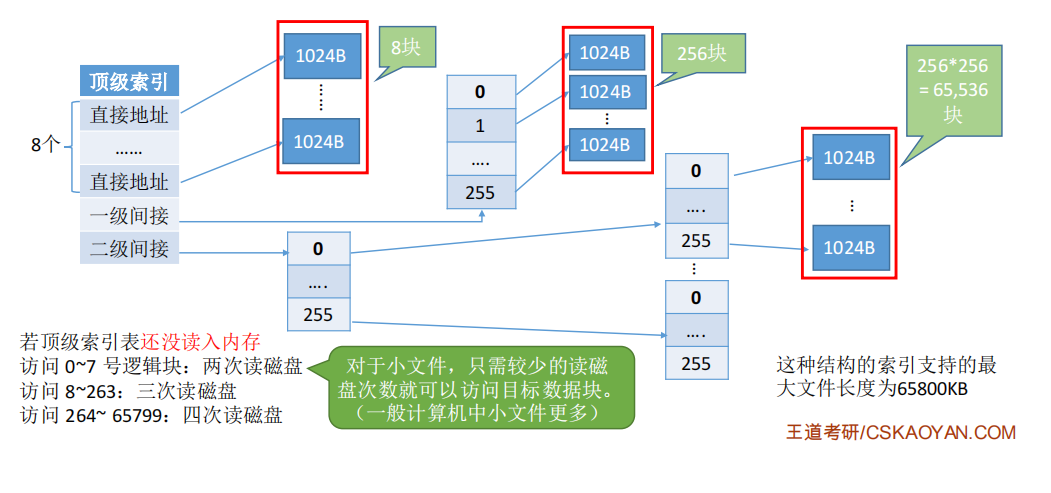
建立多层索引(原理类似于多级页表)。使第一层索引块指向第二层的索引块。还可根据文件大小的要求再建立第三层、第四层索引块。
假设磁盘块大小为1KB,一个索引表项占4B,则一个磁盘块只能存放256个索引项。
若某文件采用两层索引,则该文件的最大长度可以到256* 256* 1KB=65,536KB=64MB
可根据逻辑块号算出应该查找索引表中的哪个表项。
如:要访问1026号逻辑块,则1026/256=4,1026%256=2
因此可以先将一级索引表调入内存,查询4号表项,将其对应的二级索引表调入内存,再查询二级索引表的2号表项即可知道1026号逻辑块存放的磁盘块号了。访问目标数据块,需要3次磁盘I/O。若采用三层索引,则文件的最大长度为256* 2562561KB=16GB , 类似的,访问目标数据块,需要4次磁盘I/O

混合索引
==多种索引分配方式的结合。==
例如,一个文件的顶级索引表中,既包含直接地址索引(直接指向数据块),又包含一级间接索引(指向单层索引表)、还包含两级间接索引(指向两层索引表)。
对于小文件,只需较少的读磁盘次数就可以访问目标数据块 (一般计算机中小文件更多)
总结
-
链接方案 : 如果索引表太大,一个索引块装不下,那么可以将多个索引块链接起来存放。
缺点: 若文件很大,索引表很长,就需要将很多个索引块链接起来。想要找到i号索引块,必须先依次读入0~i-1号索引块,这就导致磁盘I/O次数过多,查找效率低下。 => 引出 多级索引
-
多层索引: 建立多层索引(==原理类似于多级页表==)。使第一层索引块指向第二层的索引块。还可根据文件大小的要求再建立第三层、第四层索引块。采用K层索引结构,且顶级索引表未调入内存,则访问一个数据块只需要K+1次读磁盘操作。 缺点:即使是小文件,访问一个数据块依然需要K+1次读磁盘。
-
混合索引: 多种索引分配方式的结合。例如,一个文件的顶级索引表中,既包含直接地址索引(直接指向数据块),又包含一级间接索引(指向单层索引表)、还包含两级间接索引(指向两层索引表)。优点:对于小文件来说,访问一个数据块所需的读磁盘次数更少。
①要会根据多层索引、混合索引的结构计算出文件的最大长度(Key:各级索引表最大不能超过一个块);
②要能自己分析访问某个数据块所需要的读磁盘次数(Key:FCB中会存有指向顶级索引块的指针,因此可以根据FCB读入顶级索引块。每次读入下一级的索引块都需要一次读磁盘操作。另外,要注意题目条件一一顶级索引块是否已调入内存)
三种分配方式总结
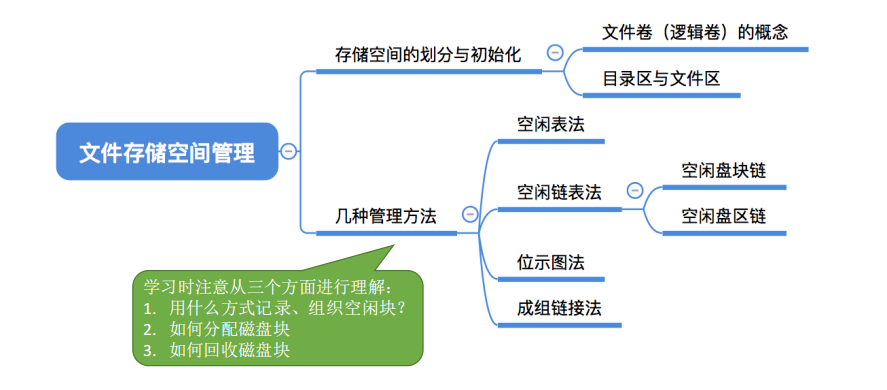
4.1.5.对空闲磁盘块的管理–文件存储空间管理
1.文件卷
存储空间的划分 : 将物理磁盘划分为一个个文件卷(逻辑卷、逻辑盘)。所谓的文件卷就相当于电脑上的C盘,D盘等。

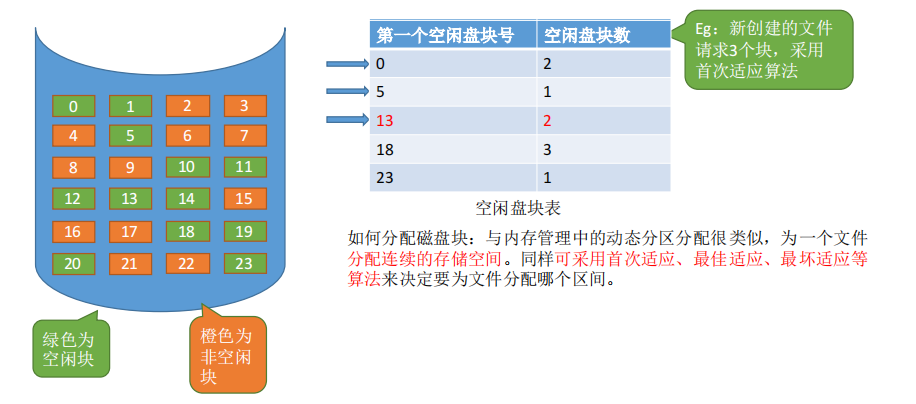
2.空闲表法
为一个磁盘创建一个表,来存储空闲磁盘块的位置。
如何分配磁盘块 : 与内存管理中的动态分区分配很类似,为一个文件分配连续的存储空间。同样可采用==首次适应、最佳适应、最坏适应等算法==来决定要为文件分配哪个区间。
如何回收磁盘块: 与内存管理中的动态分区分配很类似,当回收某个存储区时需要有四种情况―—
- 回收区的前后都没有相邻空闲区;
- 回收区的前后都是空闲区;
- 回收区前面是空闲区;
- 回收区后面是空闲区。
总之,回收时需要注意表项的合并问题。
3.空闲链表法
空闲链表法分为空闲盘块链和空闲盘区链。
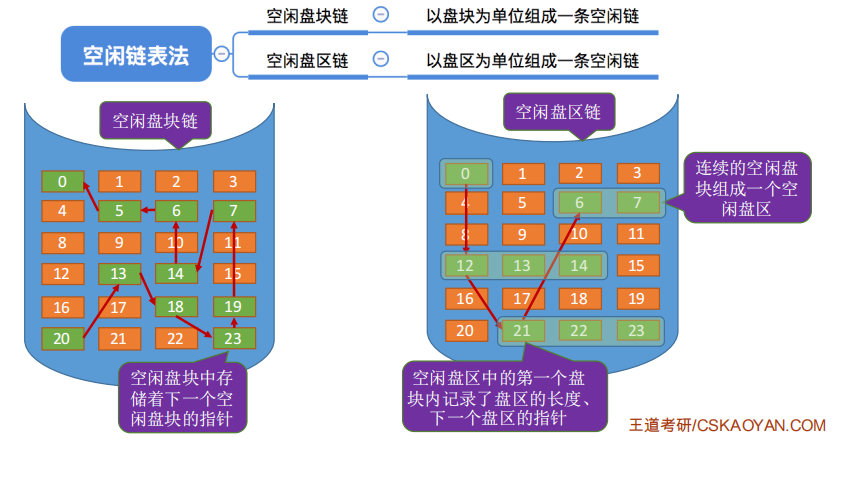
1.空闲盘块链
操作系统保存着链头、链尾指针。
- 如何分配: 若某文件申请K个盘块,则从链头开始依次摘下K个盘块分配,并修改空闲链的链头指针。
- 如何回收 : 回收的盘块依次挂到链尾,并修改空闲链的链尾指针。
适用于离散分配的物理结构。为文件分配多个盘块时可能要重复多次操作。
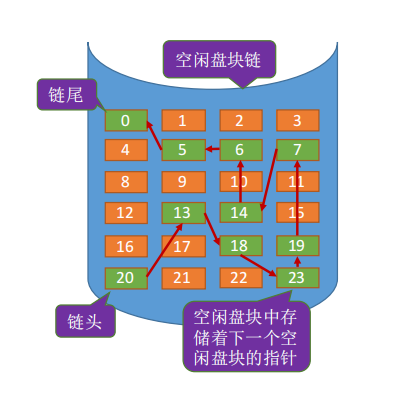
2.空闲盘区链
操作系统保存着链头、链尾指针。
如何分配: 若某文件申请K个盘块,则可以采用首次适应、最佳适应等算法,从链头开始检索,按照算法规则找到一个大小符合要求的空闲盘区,分配给文件。若没有合适的连续空闲块,也可以将不同盘区的盘块同时分配给一个文件,注意分配后可能要修改相应的链指针、盘区大小等数据。
如何回收:
- 若回收区和某个空闲盘区相邻,则需要将回收区合并到空闲盘区中。
- 若回收区没有和任何空闲区相邻,将回收区作为单独的一个空闲盘区挂到链尾。
离散分配、连续分配都适用。为一个文件分配多个盘块时效率更高
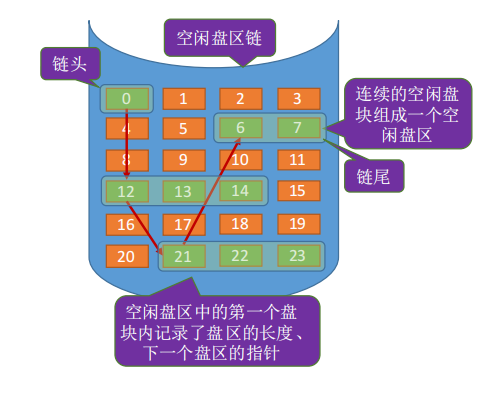
4.位示图法
位示图: 每个二进制位对应一个盘块。
在本例中,“0”代表盘块空闲,“1”代表盘块已分配。位示图一般用连续的“字”来表示,如本例中一个字的字长是16位,字中的每一位对应一个盘块。因此可以用(字号,位号)对应一个盘块号。当然有的题目中也描述为(行号,列号)
(字号,位号)=(i j) 的二进制位对应的盘块号 b= ni + j
b号盘块对应的字号i = b/n,位号j = b%n。
如何分配:若文件需要K个块,
①顺序扫描位示图,找到K个相邻或不相邻的“0”;
②根据字号、位号算出对应的盘块号,将相应盘块分配给文件;
③将相应位设置为“1”。
如何回收:
①根据回收的盘块号计算出对应的字号、位号;
②将相应二进制位设为“0”。
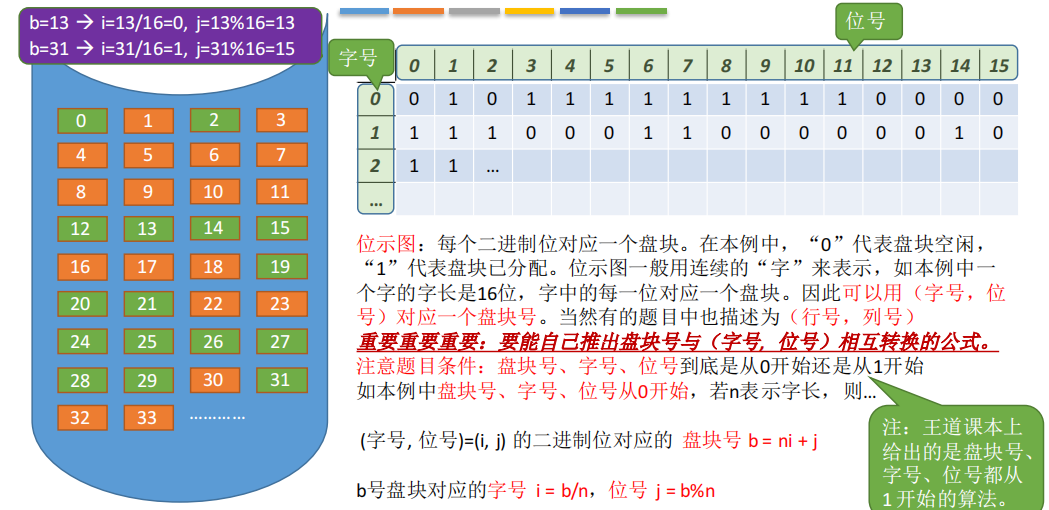
5.成组链接法
空闲表法、空闲链表法不适用于大型文件系统,因为空闲表或空闲链表可能过大。
UNIX系统中采用了成组链接法对磁盘空闲块进行管理。
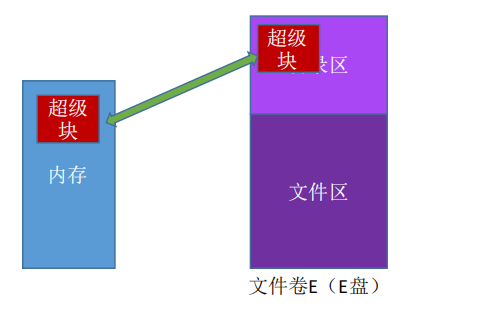
文件卷的目录区中专门用一个磁盘块作为“==超级块==”,当系统启动时需要将超级块读入内存。
并且要保证内存与外存中的“超级块”数据一致。如图所示。
超级块中存储的内容
-
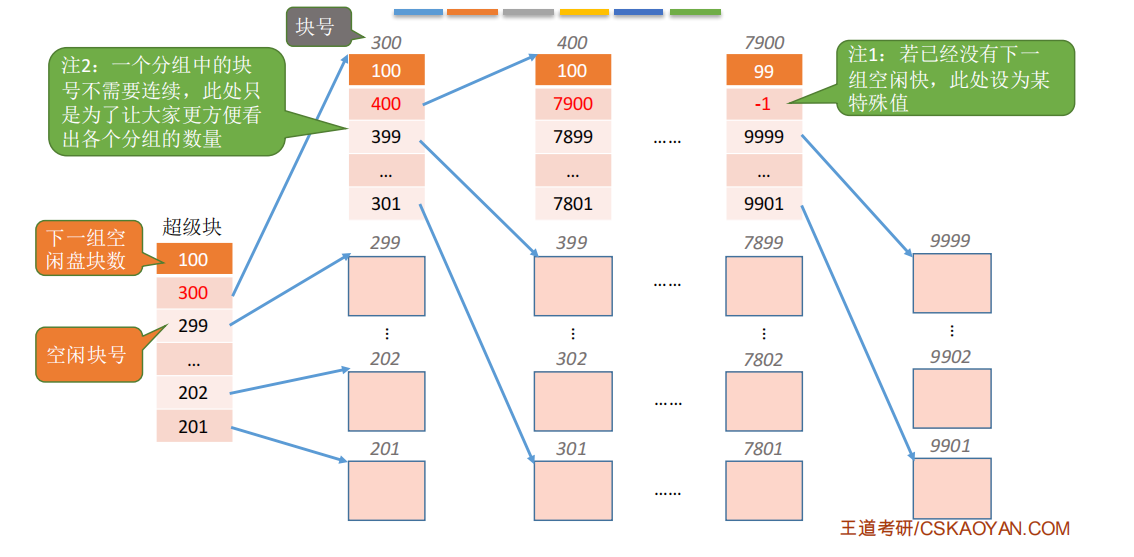
如何分配?
Eg :需要100个空闲块
①检查第一个分组的块数是否足够。100=100,是足够的。②分配第一个分组中的100个空闲块。但是由于300号块内存放了再下一组的信息,因此300号块的数据需要复制到超级块中。
Eg :需要1个空闲块
①检查第一个分组的块数是否足够。1<100,因此是足够的。②分配第一个分组中的1个空闲块,并修改相应数据
-
如何回收?
Eg :假设每个分组最多为100个空闲块,此时第一个分组已有99个块,还要再回收一块。Eg : 假设每个分组最多为100个空闲块,此时第一个分组已有100个块,还要再回收一块。需要将超级块中的数据复制到新回收的块中,并修改超级块的内容,让新回收的块成为第一个分组。
4.1.6.文件的基本操作
1.创建文件
进行Create系统调用时,需要提供的几个主要参数:
-
所需的外存空间大小(如:一个盘块,即1KB)
-
文件存放路径(“D:/Demo”)
-
文件名(这个地方默认为“新建文本文档.txt”)
操作系统在处理Create系统调用时,主要做了两件事:
1.在外存中找到文件所需的空间(结合上小节学习的空闲链表法、位示图、成组链接法等管理策略,找到空闲空间)
2.根据文件存放路径的信息找到该目录对应的目录文件(此处就是 D:/Demo目录),在目录中创建该文件对应的目录项。目录项中包含了文件名、文件在外存中的存放位置等信息。
2.删除文件
进行Delete系统调用时,需要提供的几个主要参数:
1.文件存放路径(“D:/Demo”)
2.文件名(“test.txt”)
操作系统在处理Delete系统调用时,主要做了几件事:
1.根据文件存放路径找到相应的目录文件,从目录中找到文件名对应的目录项。
2.根据该目录项记录的文件在外存的存放位置、文件大小等信息,回收文件占用的磁盘块。(回收磁盘块时,根据空闲表法、空闲链表法、位图法等管理策略的不同,需要做不同的处理)
3.从目录表中删除文件对应的目录项。
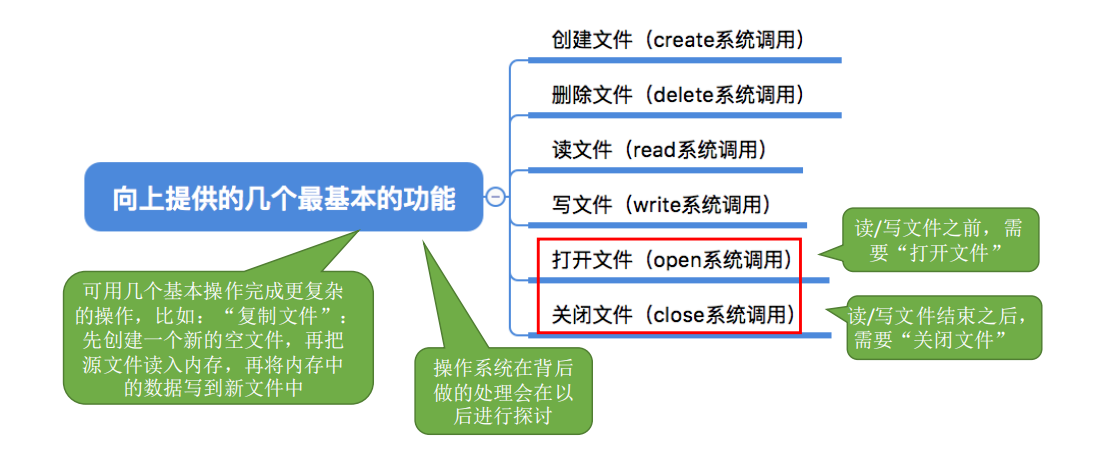
3.打开文件
在很多操作系统中,在对文件进行操作之前,要求用户先使用open系统调用“打开文件”,需要提供的几个主要参数:
- 文件存放路径(“D:/Demo”)
- 文件名( “test.txt”)
- 要对文件的操作类型(如:r只读;rw读写等)
操作系统在处理open系统调用时,主要做了几件事:
1.根据文件存放路径找到相应的目录文件,从目录中找到文件名对应的的目录项,并检查该用户是否有指定的操作权限。
2.将目录项复制到内存中的“打开文件表”中。并将对应表目的编号返回给用户。之后用户使用打开文件表的编号来指明要操作的文件。

- 需要注意的是,有两张打开文件表,一个是进程自带的,另一个是系统的(只有一张)。

4.关闭文件
进程使用完文件后,要“关闭文件”。
操作系统在处理Close系统调用时,主要做了几件事:
1.将进程的打开文件表相应表项删除
2.回收分配给该文件的内存空间等资源
3.系统打开文件表的打开计数器count 减1,若count =0,则删除对应表项。
5.读文件
进程使用read系统调用完成写操作。
需要指明是哪个文件(在支持“打开文件”操作的系统中,只需要提供文件在打开文件表中的索引号即可),
还需要指明要读入多少数据(如:读入1KB)、
指明读入的数据要放在内存中的什么位置。
操作系统在处理read 系统调用时,会从读指针指向的外存中,将用户指定大小的数据读入用户指定的内存区域中。
6.写文件
进程使用write系统调用完成写操作,
需要指明是哪个文件(在支持“打开文件”操作的系统中,只需要提供文件在打开文件表中的索引号即可),
还需要指明要写出多少数据(如:写出1KB)、
写回外存的数据放在内存中的什么位置
操作系统在处理write系统调用时,会从用户指定的内存区域中,将指定大小的数据写回写指针指向的外存。
4.1.7.文件共享
实现多个用户共享同一个文件
1.基于索引节点的共享方式(硬链接)
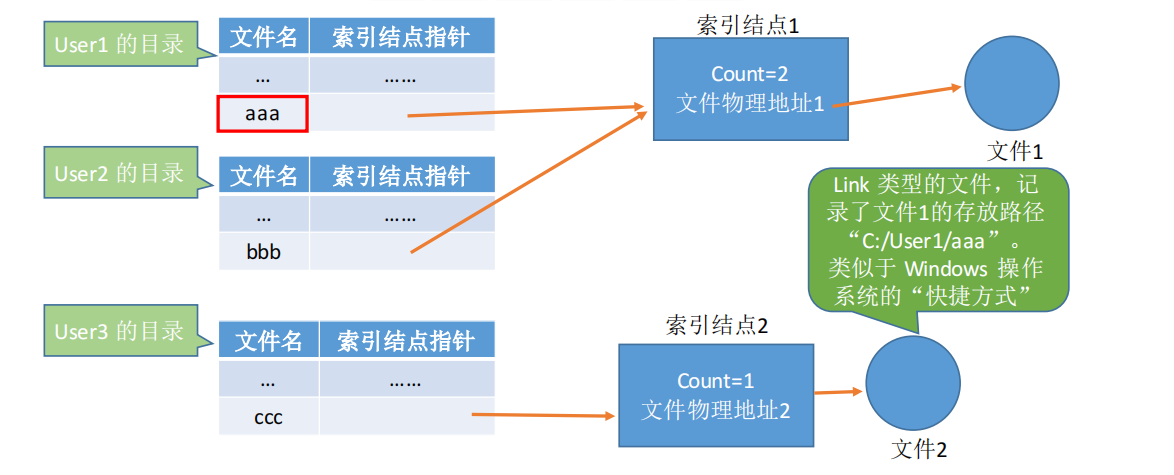
知识回顾: 索引结点,是一种文件目录瘦身策略。由于检索文件时只需用到文件名,因此可以将除了文件名之外的其他信息放到索引结点中。这样目录项就只需要包含文件名、索引结点指针。
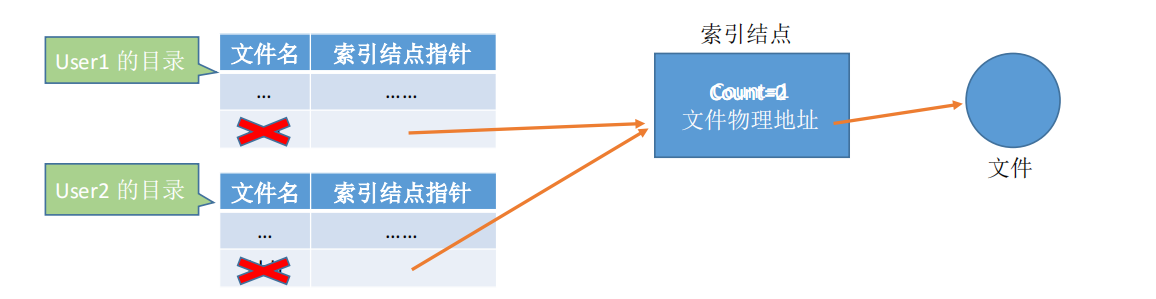
索引结点中设置一个链接计数变量 count,用于表示链接到本索引结点上的用户目录项数。
若count =2,说明此时有两个用户目录项链接到该索引结点上,或者说是有两个用户在共享此文件。若某个用户决定“删除”该文件,则只是要把用户目录中与该文件对应的目录项删除,且索引结点的count值减1。
若count>0,说明还有别的用户要使用该文件,暂时不能把文件数据删除,否则会导致指针悬空。当count =0时系统负责删除文件。
2.基于符号链的共享方式(软链接)
windows的快捷方式
当User3访问“ccc”时,操作系统判断文件“ccc”属于Link类型文件,于是会根据其中记录的路径层层查找目录,最终找到User1的目录表中的“aaa”表项,于是就找到了文件1的索引结点。类似于快捷方式。
4.1.8.文件保护
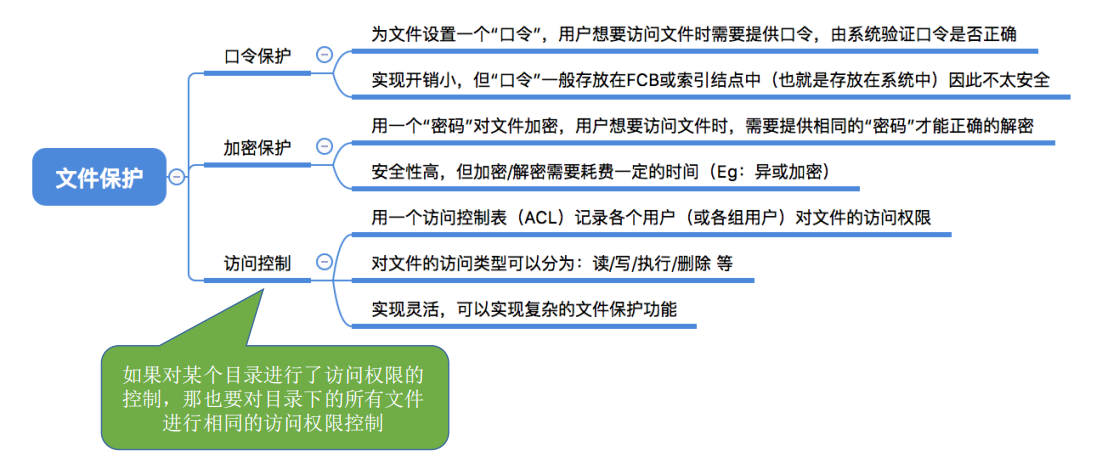
1.口令保护
就比如登录的时候输入密码
为文件设置一个“口令”(如: abc112233),用户请求访问该文件时必须提供“口令”。
口令一般存放在文件对应的FCB或索引结点中。用户访问文件前需要先输入“口令”,操作系统会将用户提供的口令与FCB中存储的口令进行对比,如果正确,则允许该用户访问文件。
- 优点: 保存口令的空间开销不多,验证口令的时间开销也很小。
- 缺点 : 正确的“口令”存放在系统内部,不够安全。
2.加密保护
改变文件的存储本身
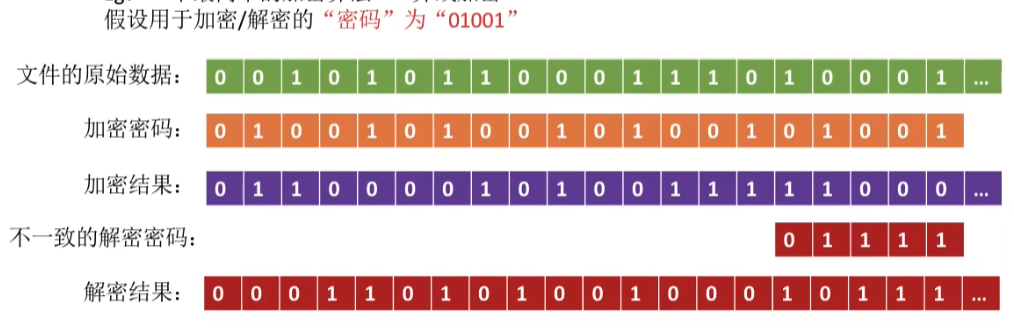
使用某个“密码”对文件进行加密,在访问文件时需要提供正确的“密码”才能对文件进行==正确的解密==。
Eg: 一个最简单的加密算法――异或加密。
假设用于加密/解密的“密码”为“01001”。
- 优点: 保密性强,不需要在系统中存储“密码”。
- 缺点: 编码/译码,或者说==加密/解密==要花费一定时间。
3.访问控制
在每个文件的FCB(或索引结点)中增加一个访问控制列表(Access-Control List, ACL),
该表中记录了各个用户可以对该文件执行哪些操作。
如图所示:

精简的访问列表: 以“组”为单位,标记各“组”用户可以对文件执行哪些操作。
如:分为系统管理员、文件主、文件主的伙伴、其他用户几个分组。当某用户想要访问文件时,系统会检查该用户所属的分组是否有相应的访问权限。
这个可以参看 linux 的 用户/用户组管理

4.总结
4.1.9.文件的层次结构
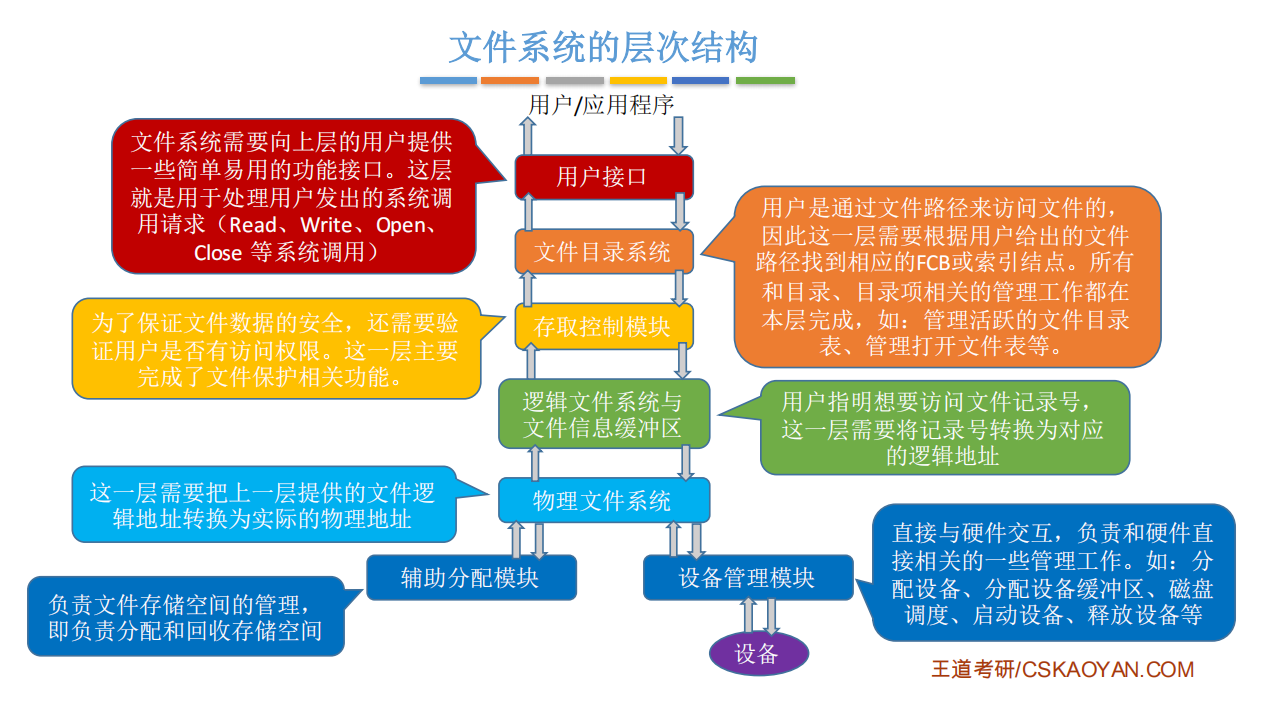
用一个例子来辅助记忆文件系统的层次结构:
假设某用户请求删除文件“ D:/工作目录/学生信息.xlsx ”的最后100条记录。
- 用户需要通过操作系统提供的接口发出上述请求一用户接口。
- 由于用户提供的是文件的存放路径,因此需要操作系统一层一层地查找目录,找到对应的目录项――文件目录系统
- 不同的用户对文件有不同的操作权限,因此为了保证安全,需要检查用户是否有访问权限―一存取控制模块(存取控制验证层)
- 验证了用户的访问权限之后,需要把用户提供的“记录号”转变为对应的逻辑地址――逻辑文件系统与文件信息缓冲区
- 知道了目标记录对应的逻辑地址后,还需要转换成实际的物理地址――物理文件系统
- 要删除这条记录,必定要对磁盘设备发出请求――设备管理程序模块
- 删除这些记录后,会有一些盘块空闲,因此要将这些空闲盘块回收――辅助分配模块。
4.2.1.磁盘结构
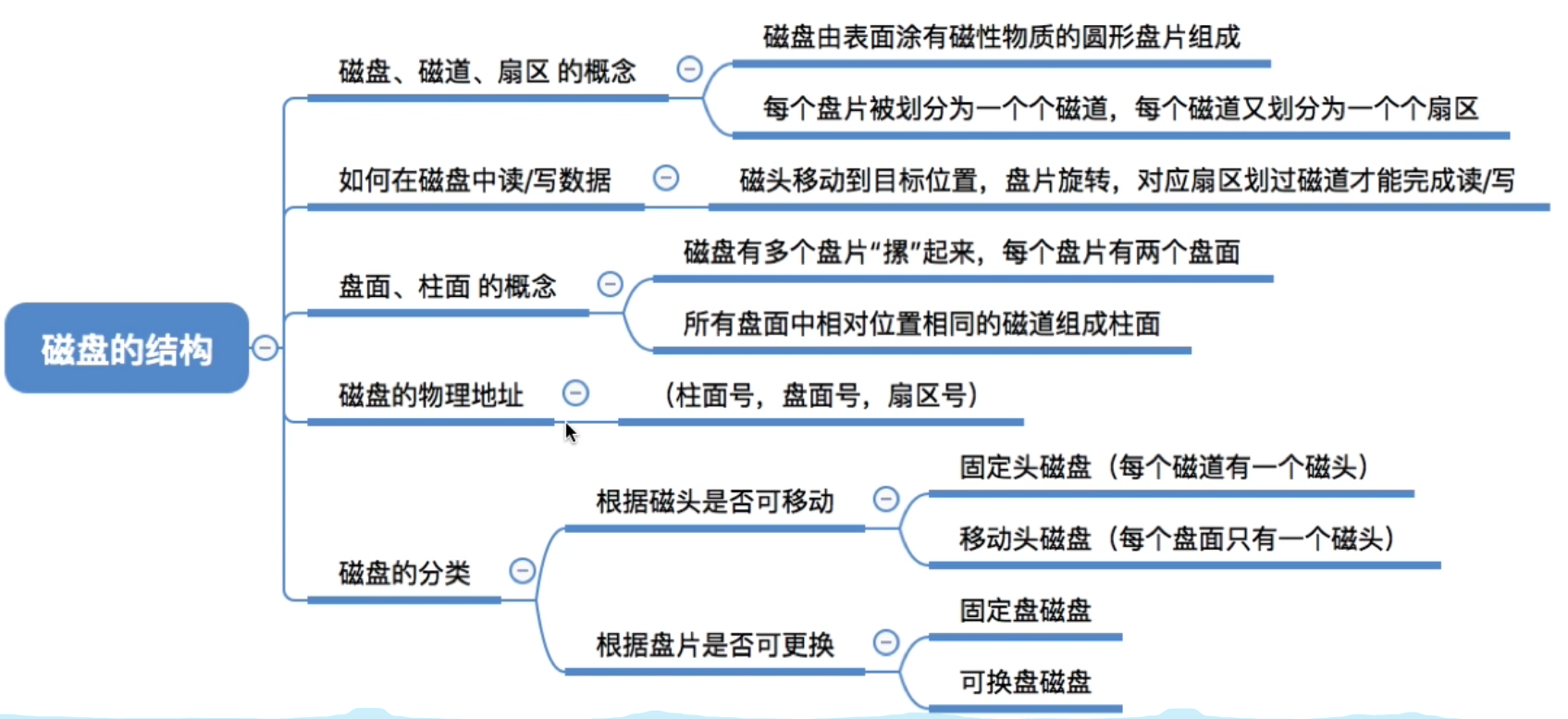
磁盘的表面由一些磁性物质组成,可以用这些磁性物质来记录二进制数据
磁盘的盘面被划分成一个个磁道。这样的一个“圈”就是一个磁道。
一个磁道又被划分成一个个扇区,每个扇区就是一个“磁盘块”。各个扇区存放的数据量相同(如1KB)。
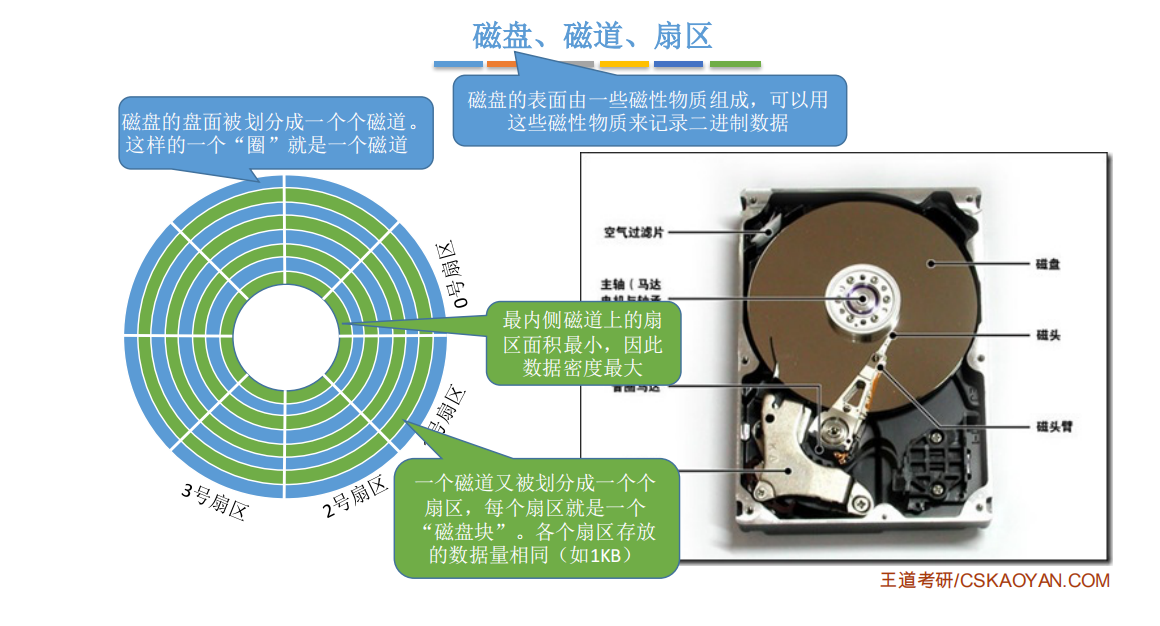

柱面
所有盘面中相对位置相同的磁道组成柱面
比如下面的这个图中 , 黄色的圆圈 就构成了柱面
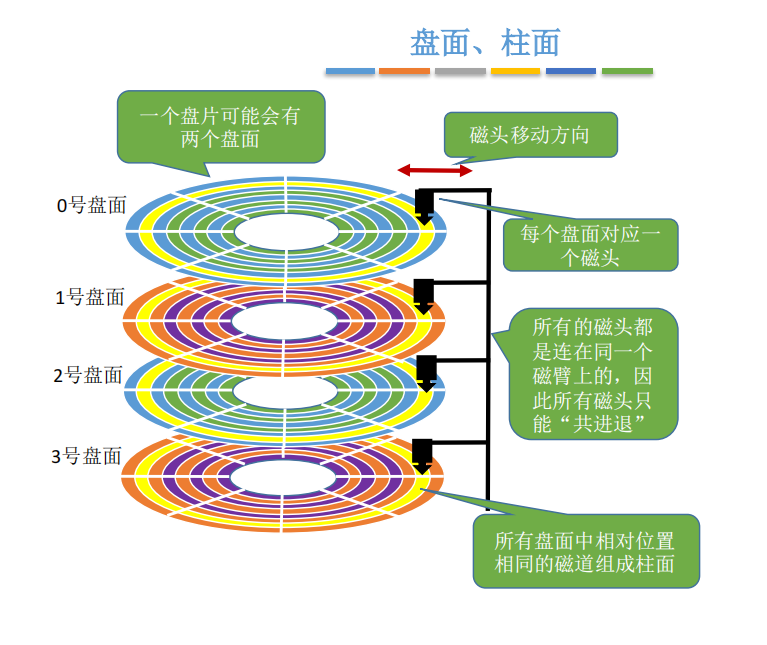
- 可用(柱面号,盘面号,扇区号)来定位任意一个“磁盘块”。
- 可根据该地址读取一个“块”
- 根据“柱面号”移动磁臂,让磁头指向指定柱面;
- 激活指定盘面对应的磁头;
- 磁盘旋转的过程中,指定的扇区会从磁头下面划过,这样就完成了对指定扇区的读/写。
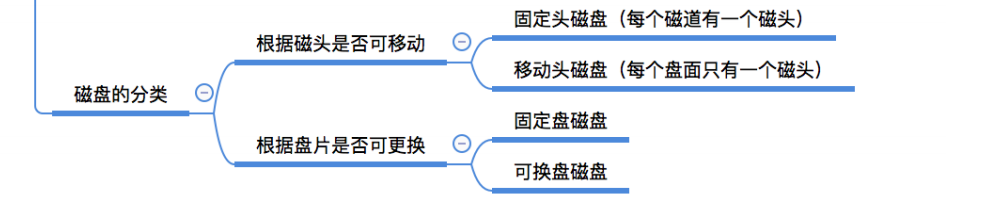
磁盘分类
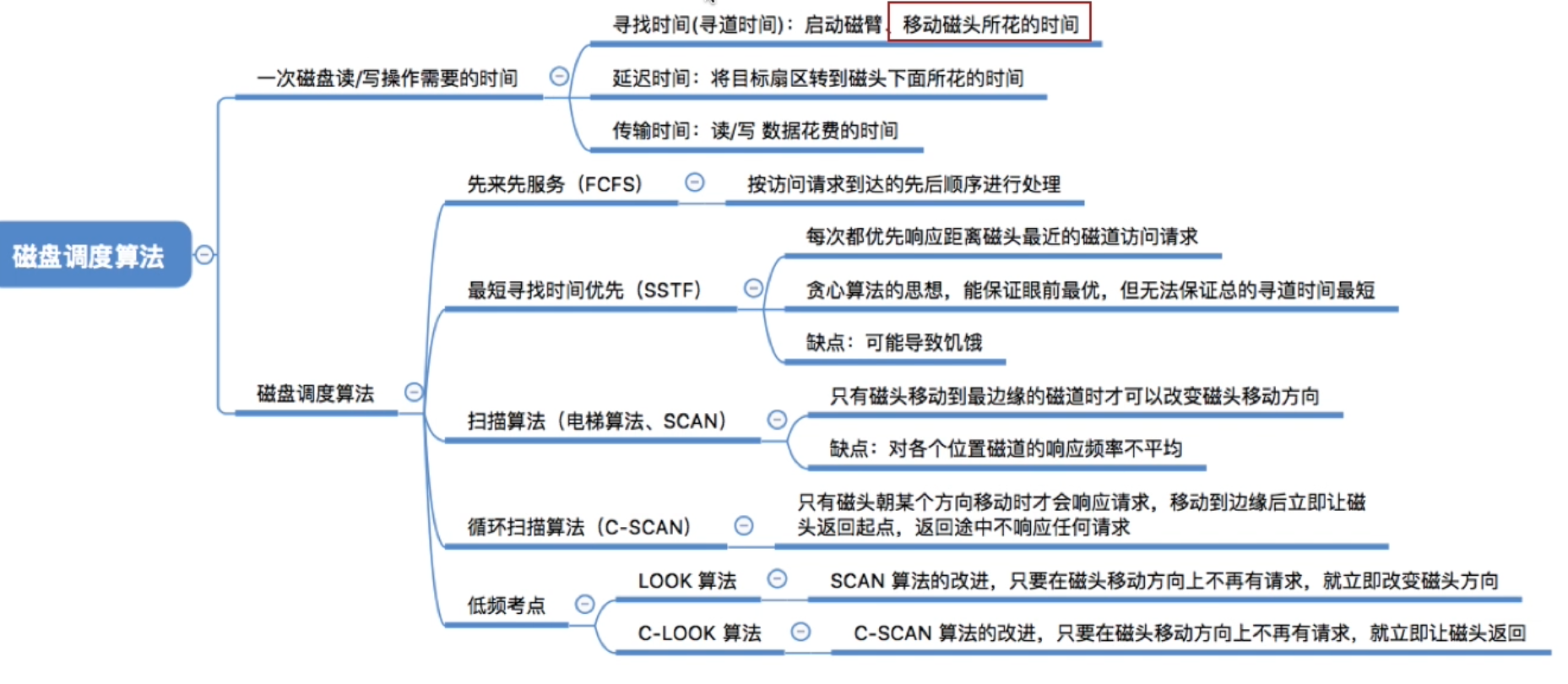
4.2.2.磁盘调度算法⭐
1.一次磁盘读/写操作需要的时间
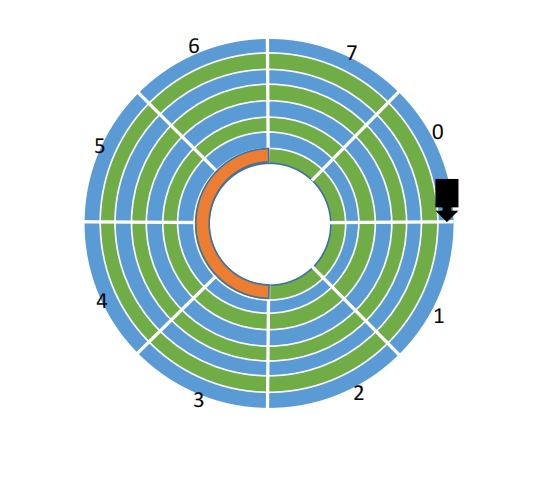
寻找时间(寻道时间)Ts:在读/写数据前,将磁头移动到指定磁道所花的时间。
-
启动磁头臂是需要时间的。假设耗时为s;
-
移动磁头也是需要时间的。假设磁头匀速移动,每跨越一个磁道耗时为m,总共需要跨越n条磁道。
则: 寻道时间 Ts = s + m * n
延迟时间T:通过旋转磁盘,使磁头定位到目标扇区所需要的时间。设磁盘转速为r(单位:转/秒,或转/分),则平均所需的延迟时间T=(1/2) * ( 1/r )= 1/2r。
1/r就是转一圈需要的时间。找到目标扇区平均需要转半圈,因此再乘以1/2
传输时间Tt:从磁盘读出或向磁盘写入数据所经历的时间,假设磁盘转速为r,此次读/写的字节数为b,每个磁道上的字节数为N。则:
传输时间 Tt = (1/r)*(b/N) = b/(rN)
每个磁道要可存N字节的数据,因此b字节的数据需要b/N个磁道才能存储。而读/写一个磁道所需的时间刚好又是转一圈所需要的时间1/r。
- 总的平均存取时间
T=Ts+ 1/2r + b/(rN)
延迟时间和传输时间都与磁盘转速相关,且为线性相关。而转速是硬件的固有属性,因此操作系统也无法优化延迟时间和传输时间。但是==操作系统的磁盘调度算法会直接影响寻道时间==。
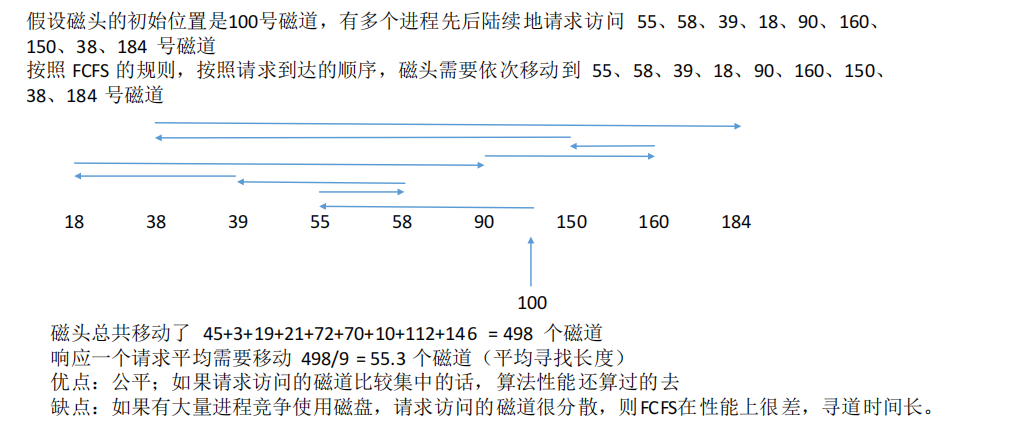
2.先来先服务算法
根据进程请求访问磁盘的先后顺序进行调度。
3. 最短寻找时间优先(SSTF)
SSTF算法会优先处理的磁道是与当前磁头最近的磁道。可以保证每次的寻道时间最短,但是并不能保证总的寻道时间最短。(其实就是贪心算法的思想,只是选择局部最优,但是总体未必最优)
可能会导致某些磁道长时间不会得到处理
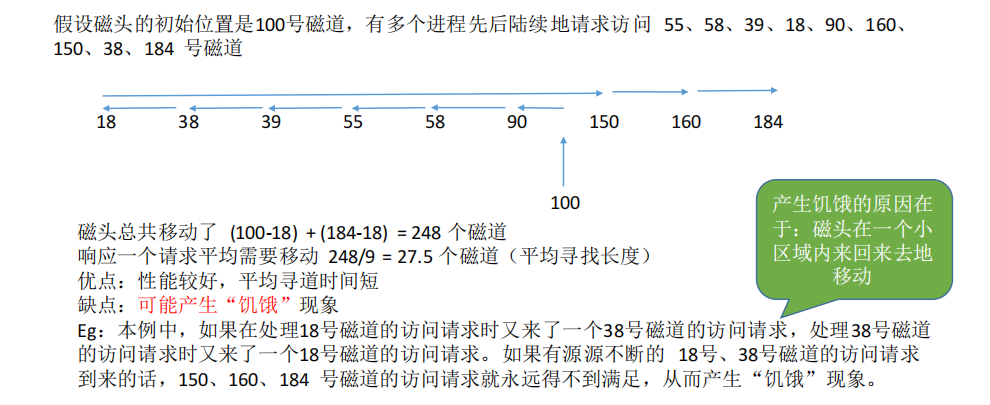
4.扫描算法(SCAN)
SSTF算法会产生饥饿的原因在于: 磁头有可能在一个小区域内来回来去地移动。
为了防止这个问题,可以规定,只有磁头移动到最外侧磁道的时候才能往内移动,移动到最内侧磁道的时候才能往外移动。
这就是扫描算法(SCAN)的思想。由于磁头移动的方式很像电梯,因此也叫电梯算法。
只有到了最边上的磁道才能改变磁头移动方向

5.LOOK调度算法
扫描算法(SCAN)中,只有到达最边上的磁道时才能改变磁头移动方向,
事实上,处理了184号磁道的访问请求之后就不需要再往右移动磁头了。
LOOK调度算法就是为了解决这个问题,如果在磁头移动方向上已经没有别的请求,就可以立即改变磁头移动方向。(边移动边观察,因此叫LOOK)。

6.循环扫描算法(C—SCAN)
SCAN算法对于各个位置磁道的响应频率不平均,而C-SCAN算法就是为了解决这个问题。
规定只有磁头朝某个特定方向移动时才处理磁道访问请求,而返回时直接快速移动至起始端而不处理任何请求。

7.C-LOOK调度算法
C-SCAN 算法的主要缺点是只有到达最边上的磁道时才能改变磁头移动方向,并且磁头返回时不一定需要返回到最边缘的磁道上。C-LOOK算法就是为了解决这个问题。如果磁头移动的方向上已经没有磁道访问请求了,就可以立即让磁头返回,并且磁头只需要返回到有磁道访问请求的位置即可。

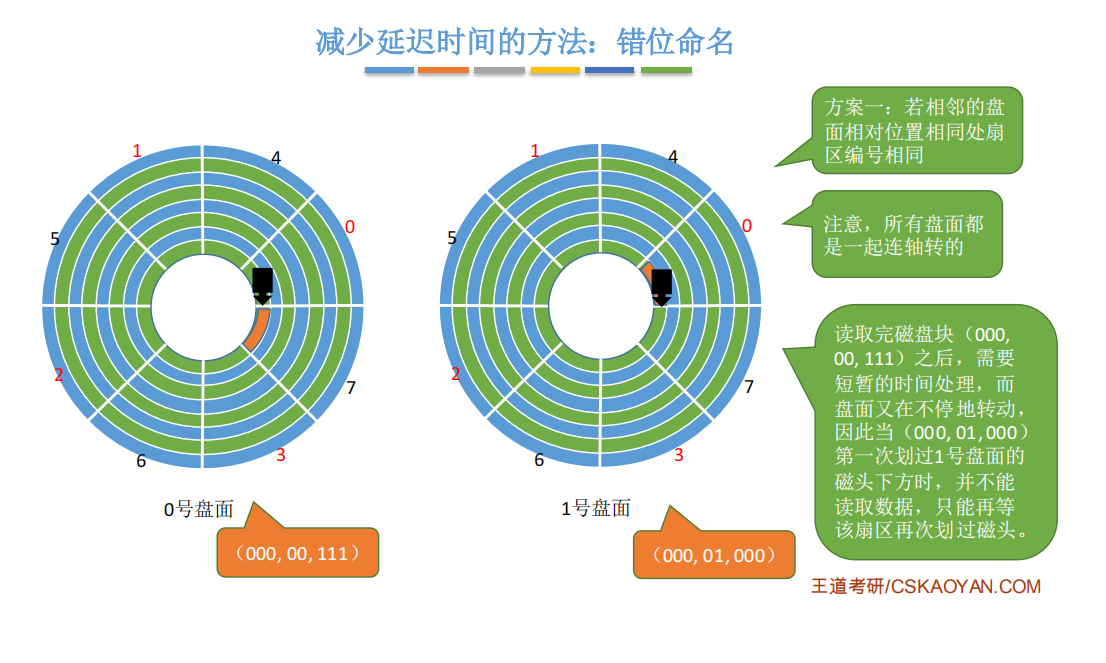
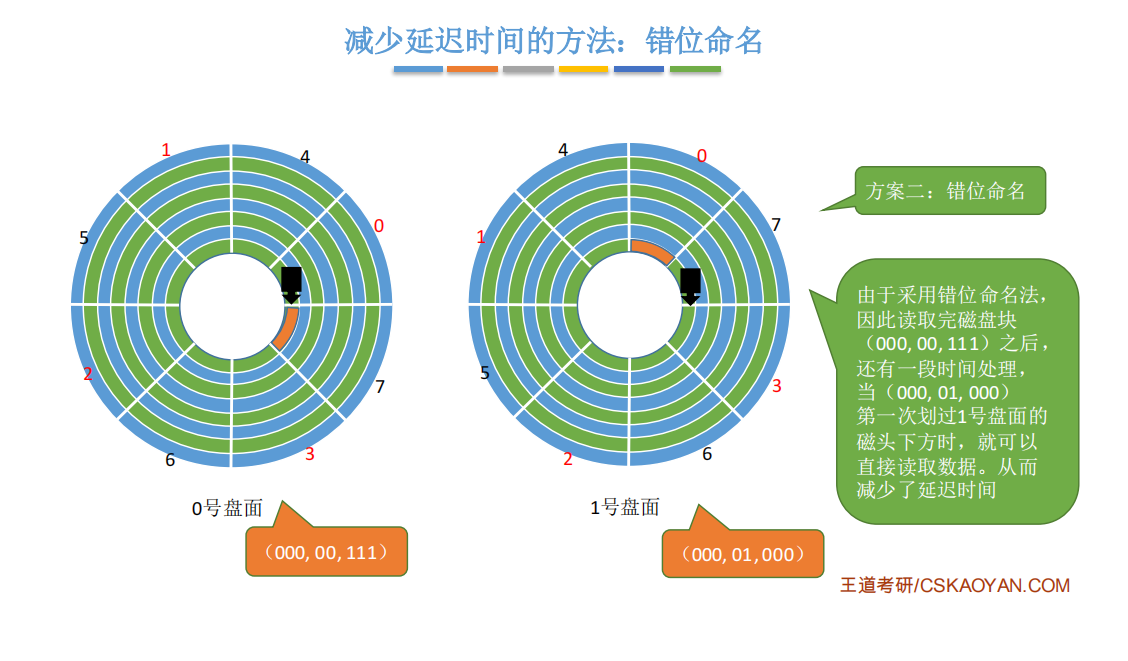
4.2.3.减少延迟时间的方法

假设要连续读取橙色区域的2、3、4扇区:
磁头读取一块的内容(也就是一个扇区的内容)后,需要一小段时间处理,而盘片又在不停地旋转
因此,如果2、3号扇区相邻着排列,则读完2号扇区后无法连续不断地读入3号扇区
必须等盘片继续旋转,3号扇区再次划过磁头,才能完成扇区读入。
结论: 磁头读入一个扇区数据后需要一小段时间处理,如果逻辑上相邻的扇区在物理上也相邻,则读入几个连续的逻辑扇区,可能需要很长的“延迟时间”。
1.交替编号
原因 : 读取完数据之后, 磁头需要一段时间去为下一次读取数据做准备
若采用交替编号的策略,即让逻辑上相邻的扇区在物理上有一定的间隔,可以使读取连续的逻辑扇区所需要的延迟时间更小。如图所示。
2.磁盘地址结构的设计
思考:为什么磁盘的物理地址是(柱面号,盘面号,扇区号),而不是(盘面号,柱面号,扇区号)?
答: 读取地址连续的磁盘块时,采用(柱面号,盘面号,扇区号)的地址结构可以减少磁头移动消耗的时间

因为磁盘的转动需要时间 , 先确定柱面号之后可以直接通过盘面号选择磁盘的盘面
如果是先确定盘面号, 那么有可能在确定盘面号的期间就已经是 刚好错过了 需要寻找的柱面
- 根本原因是 寻找 需要的柱面号 消耗的时间更长
- 启动磁头臂 与 移动磁头 花费的时间较高
假设某磁盘有8个柱面/磁道(假设最内侧柱面/磁道号为0),4个盘面,8个扇区。则可用3个二进制位表示柱面,2个二进 制位表示盘面,3个二进制位表示扇区。
若物理地址结构是(盘面号,柱面号,扇区号),且需要连续读取物理地址(00,000,000)~(00,001,111)的扇区:(00,000,000) ~ (00,000,111)转两圈可读完
之后再读取物理地址相邻的区域,即 (00,001,000)~(00,001,111), 需要启动磁头臂,将磁头移动到下一个磁道
若物理地址结构是(柱面号,盘面号,扇区号),且需要连续读取物理地址(000,00,000)~(000,01,111)的扇区:(000,00,000 ) ~(000,00,111)由盘面0的磁头读入数据
之后再读取物理地址相邻的区域,即(000,01,000)(000,01,111),由于柱面号/磁道号相同,
只是盘面号不同,因此不需要移动磁头臂。只需要激活相邻盘面的磁头即可
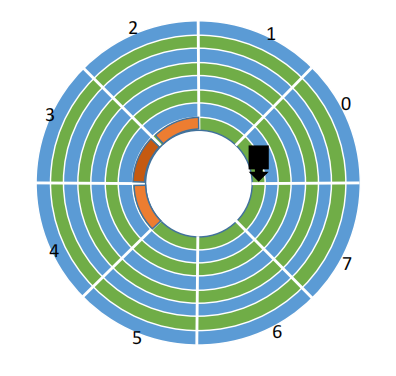
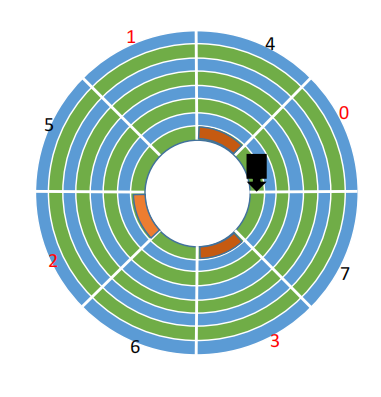
3.错位命名
错位命名就是 相邻的盘面编号不相同
注意,所有盘面都是一起连轴转的
相邻盘面相同位置 扇区编号==相同==
相邻盘面相同位置 扇区编号==不同==(错位命名)
4.2.4.磁盘的管理

1.磁盘初始化
磁盘初始化:
Step 1: 进行低级格式化(物理格式化),==将磁盘的各个磁道划分为扇区==。
一个扇区通常可分为头、数据区域(如512B大小)、尾三个部分组成。管理扇区所需要的各种数据结构一般存放在头、尾两个部分,包括扇区校验码(如奇偶校验、CRC循环冗余校验码等,校验码用于校验扇区中的数据是否发生错误)
Step 2: 将磁盘分区,每个分区由若干柱面(磁道)组成(即分为我们熟悉的C盘、D盘、E盘)

step 3: 进行逻辑格式化,创建文件系统。包括创建文件系统的根目录、初始化存储空间管理所用的数据结构(如位示图、空闲分区表)
2.引导块
-
计算机开机时需要进行一系列初始化的工作,这些初始化工作是通过执行初始化程序(自举程序)完成的。
-
初始化程序可以放在ROM(只读存储器)中。ROM中的数据在出厂时就写入了,并且以后不能再修改 。
初始化程序程序(自举程序)放在ROM中存在什么问题?万一需要更新自举程序,将会很不方便,因为ROM中的数据无法更改。如何解决呢?
-
ROM中只存放很小的“自举装入程序”。开机时计算机先运行“自举装入程序”,通过执行该程序就可找到引导块,并将完整的“自举程序”读入内存,完成初始化
-
完整的自举程序放在磁盘的启动块(即引导块/启动分区)上,启动块位于磁盘的固定位置。
-
拥有启动分区的磁盘称为启动磁盘或系统磁盘(c:盘)
3.坏块的管理
- 坏了、无法正常使用的扇区就是“坏块”。这属于硬件故障,操作系统是无法修复的。应该将坏块标记出来,以免错误地使用到它。
- 对于简单的磁盘,可以在逻辑格式化时(建立文件系统时)对整个磁盘进行坏块检查,标明哪些扇区是坏扇区,比如:在FAT表上标明。(在这种方式中,坏块对操作系统不透明)
- 对于复杂的磁盘,磁盘控制器(磁盘设备内部的一个硬件部件)会维护一个坏块链表。
在磁盘出厂前进行低级格式化(物理格式化)时就将坏块链进行初始化。
会保留一些“备用扇区”,用于替换坏块。这种方案称为扇区备用。且这种处理方式中,坏块对操作系统透明。








