
深入理解redis持久化(1):RDB持久化[redis]
众所周知 , redis之所以这么快, 很大一部分原因是因为redis中存储的数据都在内存中, 但是如果我们的服务器在运行的过程中宕机或者重启了, 内存中的数据就会直接丢失 , 因此我们在使用redis 的时候必须要将数据持久化到磁盘中 , 以备不时之需。
数据持久化就是将内存中的数据模型转换为存储模型, 以及将存储模型转换为内存中的数据模型的统称.
数据模型可以是任何数据结构或对象模型,存储模型可以是关系模型、XML、二进制流等。
cmp和Hibernate只是对象模型到关系模型之间转换的不同实现。
- 比如我们常用的mybatis就是一个持久层框架

事实上Redis 有两种持久化方案,分别是 RDB (Redis DataBase) 和 AOF (Append Only File)。
本篇涉及到redis源码 , 可以先了解redis的目录结构(37条消息) redis之源码目录结构_happytree001的博客-CSDN博客_redis源码目录
aof.c
rdb.c、rdb.hserver.c
RDB
RDB文件的创建与加载
创建
首先 , 有两个Redis命令可以用于生成RDB文件,一个是SAVE,另一个是BGSAVE。
SAVE命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止,在服务器进程阻塞期间,服务器不能处理任何命令请求
*BGSAVE ( Background saving )*命令会派生出一个子进程,然后由子进程负责创建RDB文件,服务器进程(父进程)继续处理命令请求
也就是说 BGSAVE和SAVE命令直接阻塞服务器进程的做法不同 , 不会阻塞服务器进程
创建RDB文件的实际工作由rdb.c/rdbSave 函数完成,SAVE命令和BGSAVE命令会以不同的方式调用这个函数
SAVE
1 | def SAVE(): |
BGSAVE
1 | def BGSAVE(): |
加载
在我们创建好了 rdb 文件之后, 在服务器启动的时候就会自动载入文件里面的数据
只要Redis服务器在启动时检测到RDB文件存在,它就会自动载入RDB文件。
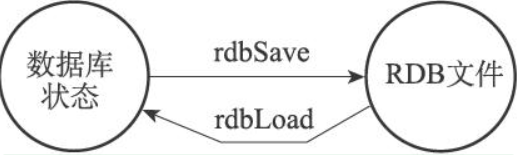
服务器在载入RDB文件期间,会一直处于阻塞状态,直到载入工作完成。
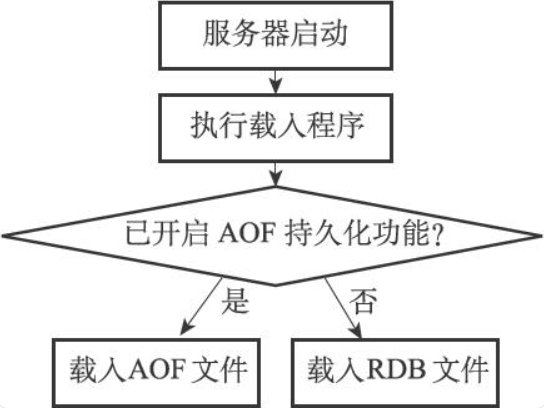
需要注意的是,因为AOF文件的更新频率通常比RDB文件的更新频率高,所以:
- 如果服务器开启了AOF持久化功能,那么服务器会优先使用AOF文件来还原数据库状态。
- 只有在AOF持久化功能处于关闭状态时,服务器才会使用RDB文件来还原数据库状态。
前面我们提到 SAVE命令会阻塞redis服务器, 因此当SAVE命令正在执行时,客户端发送的所有命令请求都会被拒绝。
只有在SAVE命令之行结束之后才能继续执行客户端发送的命令
而对于BGSAVE , 由于保存工作交给了子进程执行, 因此在执行BGSAVE的过程中redis服务器仍然可以接收请求,
不过对于客户端发送的SAVE命令会被拒绝,
服务器禁止SAVE命令和BGSAVE命令同时执行是为了避免父进程(服务器进程)和子进程同时执行两个rdbSave调用,防止产生竞争条件。
而对于客户端发送的BGSAVE命令会被服务器拒绝,也是因为同时执行两个BGSAVE命令也会产生竞争条件。
BGREWRITEAOF和BGSAVE两个命令不能同时执行:
- 如果BGSAVE命令正在执行,那么客户端发送的BGREWRITEAOF命令会被延迟到BGSAVE命令执行完毕之后执行。
- 如果BGREWRITEAOF命令正在执行,那么客户端发送的BGSAVE命令会被服务器拒绝。
设置自动保存 BGSAVE
前面我们提到使用 BGSAVE命令来进行RDB持久化不会阻塞服务器主进程 , 所以Redis允许用户通过设置服务器配置的save选项,让服务器每隔一段时间自动执行一次BGSAVE命令。
举个例子
1 | save 90 50 # 服务器在90秒之内,对数据库进行了至少50次修改。 |
我们查看redis源码可以看到 在 server.h 文件中有一个 saveparam * 类型的参数 , 对应的也就是 saveparam[]
通过注释也不难发现这就是RDB persistence=> RDB持久化
git clone git@github.com:redis/redis.git下载redis源码
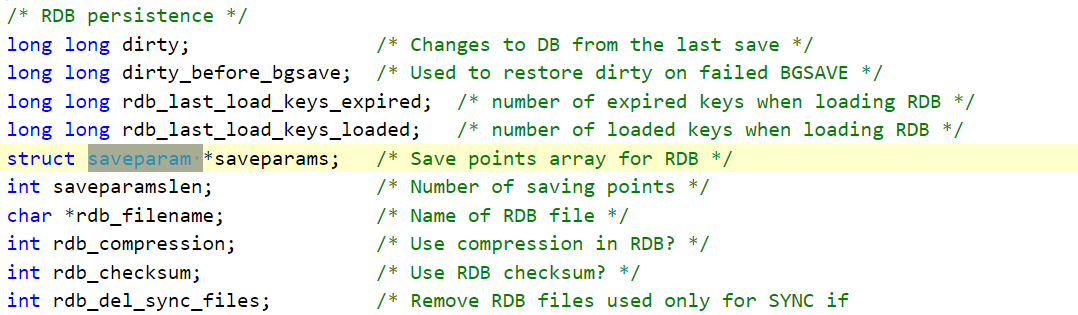
这个saveparam的参数也很简单 , 可以看到跟上面save命令的参数相对应
1 | struct saveparam { |

除此之外, server中还存在着一个 dirty计数器 以及 lastsave 参数, 分别保存了在上一次修改之后服务器对数据库的修改次数 以及 上次一成功执行SAVE命令或者BGSAVE命令的时间
-
lastsave属性是一个UNIX时间戳1
2
3typedef __time64_t time_t;
...
time_t lastsave; /* Unix time of last successful save */
那么redis是如何检查 dirty 以及 lastsave 是否到达 我们指定的SAVE指令的参数呢?
- 答案是定期的对参数进行检查
server.c 文件中有一个serverCron 函数 ,
" Redis的服务器周期性操作函数serverCron默认每隔100毫秒就会执行一次,该函数用于对正在运行的服务器进行维护,它的其中一项工作就是检查save选项所设置的保存条件是否已经满足,如果满足的话,就执行BGSAVE命令。"
——《redis设计与实现》
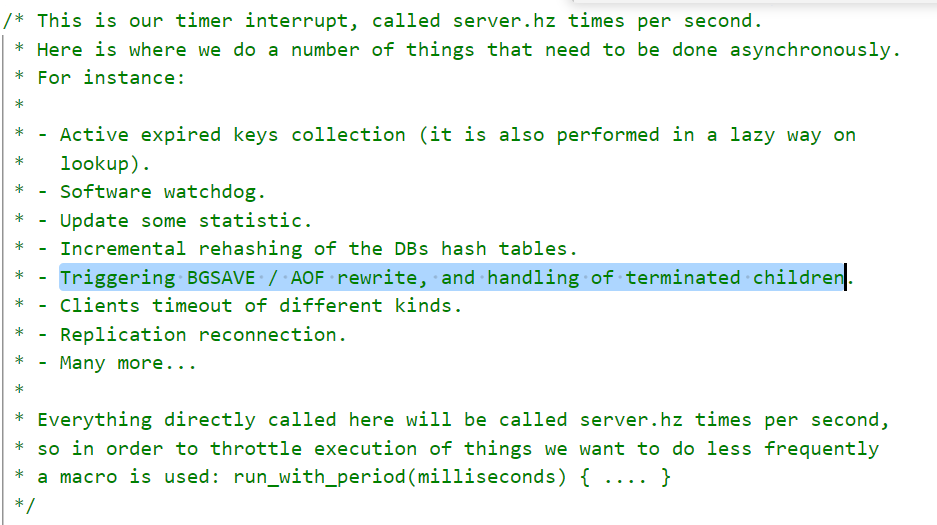
这里我们重点注意 Triggering BGSAVE / AOF rewrite, and handling of terminated children.
大概就是 触发BGSAVE/AOF重写,并处理终止的子项。 也就是我们需要找的周期性的检测 dirty 以及 lastsave参数是否到达预期设定标准
执行操作的源码如下
1 | /* Check if a background saving or AOF rewrite in progress terminated. */ |
重点关注这个for (j = 0; j < server.saveparamslen; j++) 循环, 遍历了 saveparams 数组 ,
这里对相关参数进行判断 , 只要满足了saveparams的任意一个参数 , 就会执行BGSAVE
rdbSaveBackground(SLAVE_REQ_NONE,server.rdb_filename,rsiptr,RDBFLAGS_NONE);
RDB文件结构解析
文件结构

- REDIS : 让redis快速的检查载入的文件是否是rdb文件
- db_version : rdb文件的版本
- databases : 包含着零个或任意多个数据库,以及各个数据库中的键值对数据
- EOF : rdb文件正文内容的结束标志
- check_sum : 保存校验和 , 通过对REDIS、db_version、databases、EOF四个部分的内容进行计算得出的 , 服务器在载入RDB文件时,会将载入数据所计算出的校验和与
check_sum所记录的校验和进行对比,以此来检查RDB文件是否有出错或者损坏的情况出现。
注意rdb文件中的databases可以包含多个数据库, 类似于下面的结构

并且每个非空数据库在rdb文件中都可以保存为 SELECTDB、db_number、key_value_pairs三个部分
通过字面意思我们就可以知道 , SELECTDB 后面的 db_number 表示的是数据库的号码,
“db_number保存着一个数据库号码,根据号码的大小不同,这个部分的长度可以是1字节、2字节或者5字节”
当程序读取到了db_number , 就会去选择对应的数据库, 来保证后续读取的数据是相应数据库的
key_value_pairs 存储的是数据库中的键值对的数据(包含过期时间) ,
对于不带过期时间的 数据, 保存的格式为 TYPE key value , 对于包含过期时间的数据, 格式为EXPIRETIME_MS ms TYPE key value
-
TYPE表示数据的类型, 长度为1字节 , 对应着redis中的所有数据类型 , 当程序读入rdb文件时 , 会根据数据的TYPE的值来决定如何读入和解释value的数据
REDIS_RDB_TYPE_STRINGREDIS_RDB_TYPE_LISTREDIS_RDB_TYPE_SETREDIS_RDB_TYPE_ZSETREDIS_RDB_TYPE_HASHREDIS_RDB_TYPE_LIST_ZIPLISTREDIS_RDB_TYPE_SET_INTSETREDIS_RDB_TYPE_ZSET_ZIPLISTREDIS_RDB_TYPE_HASH_ZIPLIST -
EXPIRETIME_MS 常量的长度为1字节,它告知读入程序,接下来要读入的将是一个以毫秒为单位的过期时间。
-
ms是一个8字节长的带符号整数,记录着一个以毫秒为单位的UNIX时间戳,这个时间戳就是键值对的过期时间。
接下来我们以一个简单的例子来验证上述内容,
我们简单的在redis中添加数据 , 然后SAVE持久化生成RDB文件 , 这里直接用vim 打开显示的是乱码 ,
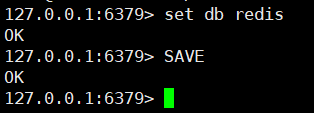

因为rdb文件为二进制格式 , 不过我们还是可以看到第一行是 REDIS0009
这里REDIS是为了让redis快速的检查载入的文件是否是rdb文件, 0009表示rdb文件的版本号 db_version , 这里的0009表示就是第九版
方便起见, 我们先下载 rdbtools ( 一款rtd文件可视化软件)
分析文件结构
使用od命令
Linux od命令 | 菜鸟教程 (runoob.com)
简单来讲od命令就是以固定的编码格式去输出文件的内容
给定-c参数可以以ASCII编码的方式打印输入文件
给定-x参数可以以十六进制的方式打印输入文件

这里我们预先存储了两条数据
FLUSHALL
set db redis
set time 0223 ex 1000000
然后我们执行SAVE命令生成rdb文件,
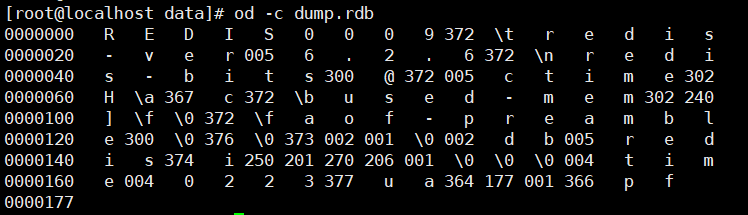
可以看到后面几行对应着我们刚刚输入的数据
根据前面的知识, 我们可以知道 这个数据库的几个部分
- SELECTDB db_number key_value_pairs
其中376代表 SELECTDB 常量,

后面的 \0 对应着我们选择的数据库
其中377 代表着常量 EOF

可以看到377前面的 0223 刚好是我们存储的time ,
那么对于我们存储的数据, 以db: redis 为例 ,
002 d b 005 r e d i s 374
其中的002 代表着我们的key 的长度, 005代表的为 value的长度
接着我们再看刚刚设置的带有过期时间的 time 数据

1 | 374 i 250 201 270 206 001 \0 \0 \0 004 t i m e 004 0 2 2 3 |
这里的数据对应关系如下:
- 374:代表特殊值EXPIRETIME_MS。
- i 250 201 270 206 001 \0 \0 : 代表着八字节长的过期时间
- \0 004 t i m e : \0表示这是一个字符串键 , 004是键的长度 , time是值
- 004 0 2 2 3:004是值的长度,0223是值。
下载rdbtools
首先需要安装python环境
https://www.python.org/downloads/release/python-3106/

点击下载installer 傻瓜式安装即可
下载rdbtools
win +R 输入cmd
pip install rdbtools 安装即可
这里我们可以通过nginx服务器来下载rdb文件
-
打开目录挂载找到rdb文件 粘贴到nginx static目录中
cp /mydata/redis/data/dump.rdb /mydata/nginx/html/static -
访问相应的路径
192.168.159.134/static/dump.rdb

接着我们通过rdb --command json dump.rdb > dump.json 操作来生成json文件 , 这里遇到了 warning , 需要我们下载 python-lzf
1 | C:\Users\dhx\Downloads\EdgeBrowserDownload>rdb --command json dump.rdb > dump.json |
下载即可
接着我们在windows控制台中输入rdb --command json dump.rdb > dump.json , 即可得到rdb文件中的数据
rdb -c memory dump.rdb --bytes 128 -f dump_memory.csv把rdb文件转换成csv文件
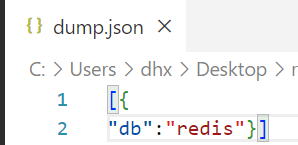
可以看到文件的内容正是之前 set db redis
这里补充一下rdb命令的参数
-h, –help #显示此帮助消息并退出;
-c FILE, –command=FILE #指定rdb文件;
-f FILE, –file=FILE #指定导出文件;
-n DBS, –db=DBS #解析指定数据库,如果不指定默认包含所有;
-k KEYS, –key=KEYS #指定需要导出的KEY,可以使用正则表达式;
-o NOT_KEYS, –not-key=NOT_KEYS #指定不需要导出的KEY,可以使用正则表达式;
-t TYPES, –type=TYPES #指定解析的数据类型,可能的值有:string,hash,set,sortedset,list;可以提供多个类型,如果没有指定,所有数据类型都返回;
-b BYTES, –bytes=BYTES #限制输出KEY大大小;
-l LARGEST, –largest=LARGEST #根据大小限制的top key;
-e ESCAPE, –escape=ESCAPE #指定输出编码,默认RAW;
使用hex-editor插件
我们在vscode中下载hex-editor插件 , 直接打开rdb文件, 也可以读出字符

这里对应着我们刚刚执行的
set db redis命令










