What is Netty
1 2 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients.
Netty 是一个异步的、基于事件驱动的网络应用框架,用于快速开发可维护、高性能的网络服务器和客户端
hello world - Netty
首先记得导入Netty的依赖
1 2 3 4 5 <dependency > <groupId > io.netty</groupId > <artifactId > netty-all</artifactId > <version > 4.1.84.Final</version > </dependency >
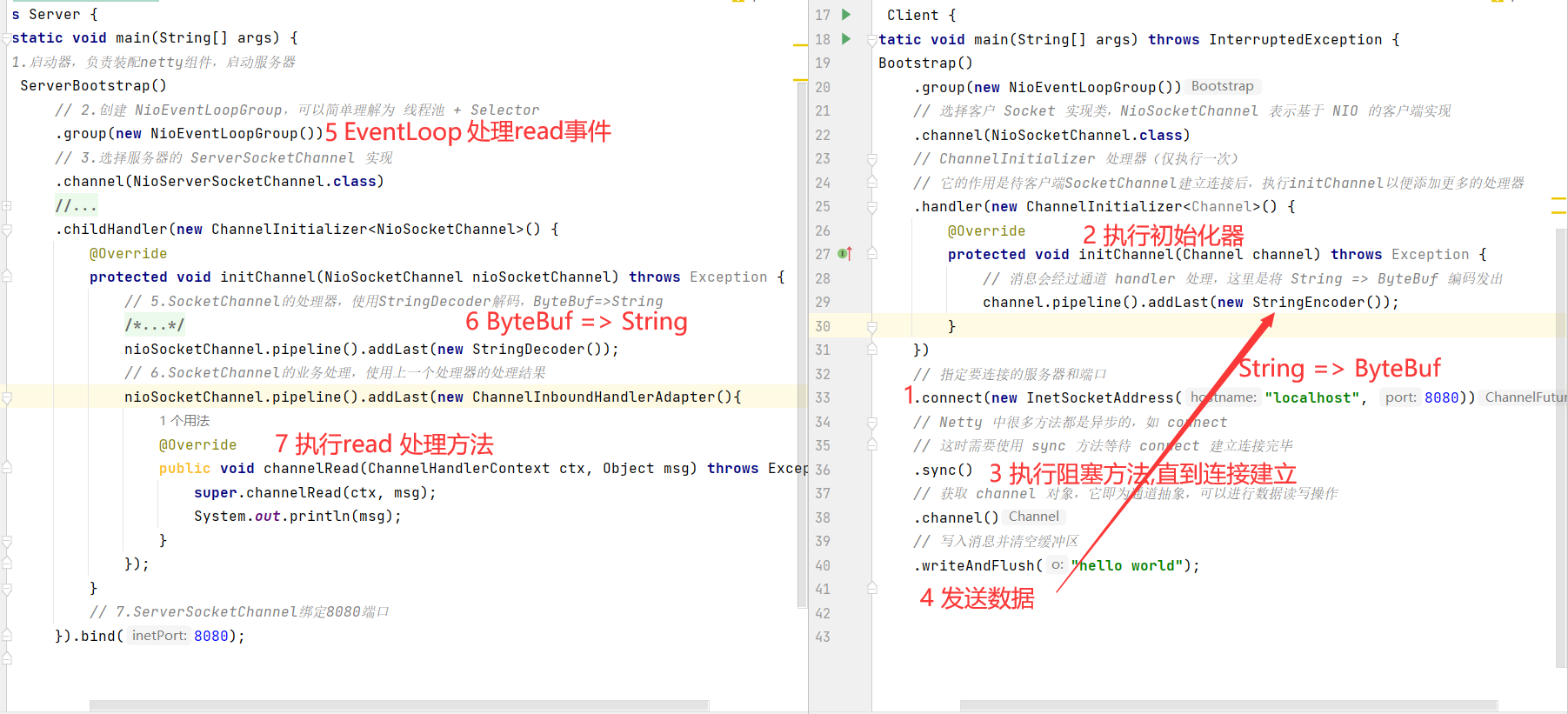
server
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class Server { public static void main (String[] args) { new ServerBootstrap () .group(new NioEventLoopGroup ()) .channel(NioServerSocketChannel.class) .childHandler(new ChannelInitializer <NioSocketChannel>() { @Override protected void initChannel (NioSocketChannel nioSocketChannel) throws Exception { nioSocketChannel.pipeline().addLast(new StringDecoder ()); nioSocketChannel.pipeline().addLast(new ChannelInboundHandlerAdapter (){ @Override public void channelRead (ChannelHandlerContext ctx, Object msg) throws Exception { super .channelRead(ctx, msg); System.out.println(msg); } }); } }).bind(8080 ); } }
client
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class Client { public static void main (String[] args) throws InterruptedException { new Bootstrap () .group(new NioEventLoopGroup ()) .channel(NioSocketChannel.class) .handler(new ChannelInitializer <Channel>() { @Override protected void initChannel (Channel channel) throws Exception { channel.pipeline().addLast(new StringEncoder ()); } }) .connect(new InetSocketAddress ("localhost" , 8080 )) .sync() .channel() .writeAndFlush("hello Netty" ); } }
发送数据的处理过程
注意点
首先我们需要明确的是 , channel 是数据的通道 , 如果把channel当成铁路 , 那么msg就是火车车厢 , 车厢里面装的就是我们传输的数据。
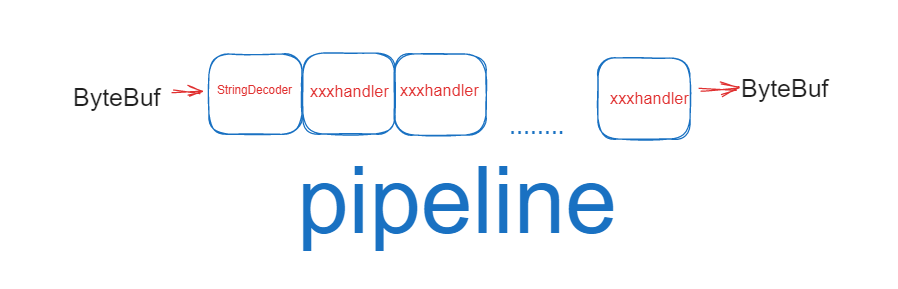
对于Pipeline , 英文的含义是 流水线
会变成其它类型对象,最后输出又变成 ByteBuf
把 handler 理解为数据的处理工序
工序有多道,合在一起就是 pipeline,pipeline 负责发布事件(读、读取完成…)传播给每个 handler, handler 对自己感兴趣的事件进行处理(重写了相应事件处理方法)
handler 分 Inbound 和 Outbound 两类
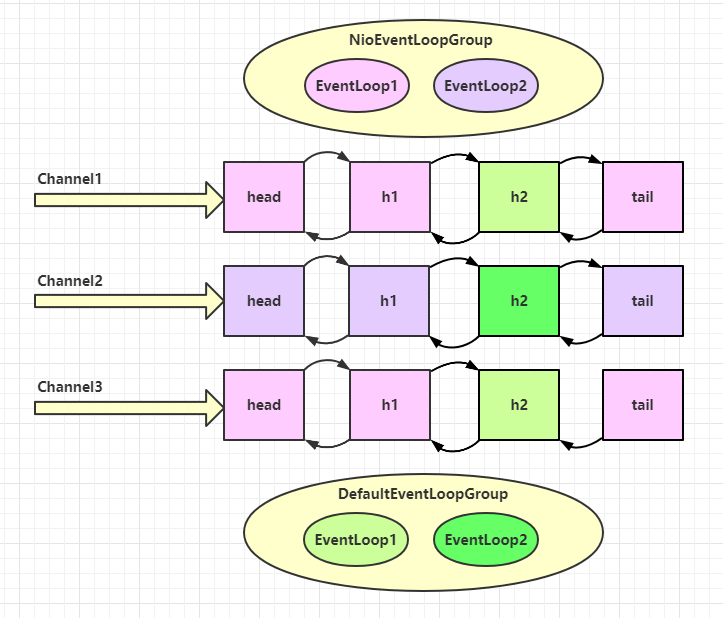
把 eventLoop 理解为处理数据的工人( worker 只负责工作(读写数据) , 不负责 accept close等 )
工人可以管理多个 channel 的 io 操作,并且一旦工人负责了某个 channel,就要负责到底(绑定)
工人既可以执行 io 操作,也可以进行任务处理,每位工人有任务队列,队列里可以堆放多个 channel 的待处理任务,任务分为普通任务、定时任务
工人按照 pipeline 顺序,依次按照 handler 的规划(代码)处理数据,可以为每道工序指定不同的工人
Netty组件
EventLoop
事件循环对象 EventLoop
EventLoop 本质是一个单线程执行器 (同时维护了一个 Selector ),里面有 run 方法处理一个或多个 Channel 上源源不断的 io 事件
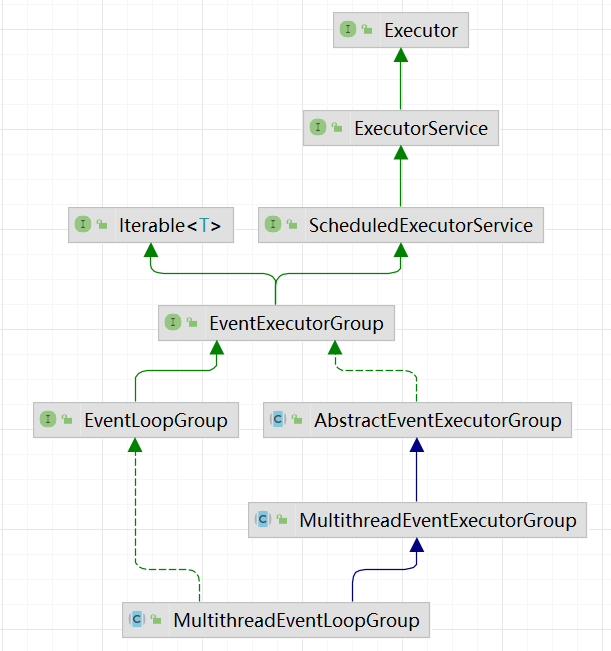
它的继承关系如下
继承自 java.util.concurrent.ScheduledExecutorService 因此包含了线程池中所有的方法
继承自 netty 自己的 OrderedEventExecutor
提供了 boolean inEventLoop(Thread thread) 方法判断一个线程是否属于此 EventLoop
提供了 EventLoopGroup parent() 方法来看看自己属于哪个 EventLoopGroup
事件循环组 EventLoopGroup
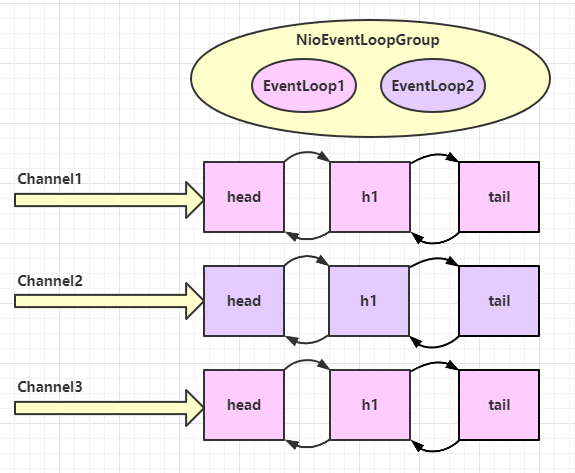
EventLoopGroup 是一组 EventLoop ,Channel 一般会调用 EventLoopGroup 的 register 方法来绑定其中一个 EventLoop,后续这个 Channel 上的 io 事件都由此 EventLoop 来处理(保证了 io 事件处理时的线程安全)
继承自 netty 自己的 EventExecutorGroup
实现了 Iterable 接口提供遍历 EventLoop 的能力
另有 next 方法获取集合中下一个 EventLoop
关于NioEventLoop 的构造方法 , 如果我们默认指定 0 (不如输入任何的参数)
那么实际上的参数就是
DEFAULT_EVENT_LOOP_THREADS = Math.max(1, SystemPropertyUtil.getInt("io.netty.eventLoopThreads", NettyRuntime.availableProcessors() * 2));
也就是我们的CPU核心数量 * 2
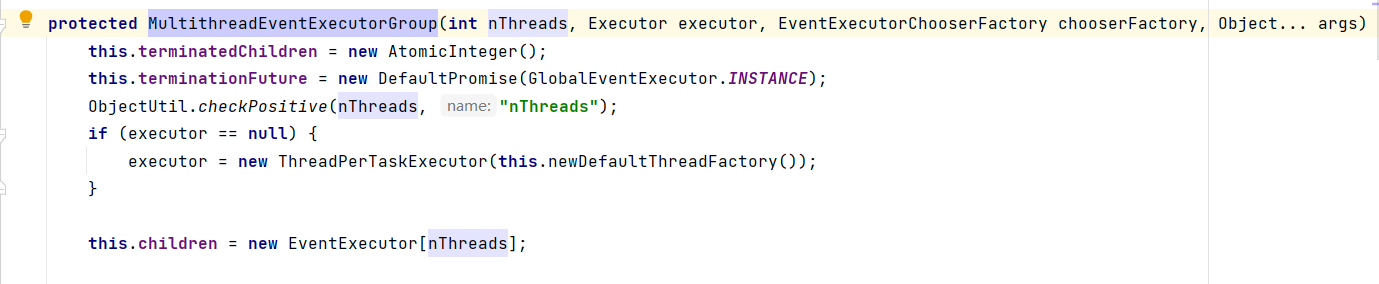
我们通过查看源码可以发现 , 我们传入的参数nThreads , 实际上被用来指定 事件执行器的个数
io.netty.util.concurrent.MultithreadEventExecutorGroup#MultithreadEventExecutorGroup()
测试代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class TestEventLoop { public static void main (String[] args) { NioEventLoopGroup group = new NioEventLoopGroup (2 ); EventLoop next = group.next(); group.next().scheduleAtFixedRate(() -> { log.info("adorabled4" ); }, 0 , 1 , TimeUnit.SECONDS); log.debug("main" ); } }
注意 : IDEA默认的断点类型是阻塞所有的线程 , 可以右键点击来进行断点类型的编辑
NioEventLoop 一旦与 Client的 Channel进行了连接, 就会直接绑定 , channel之后再发数据都是同一个EventLoop进行处理
接着我们增加handler的个数进行测试
run server
debug client
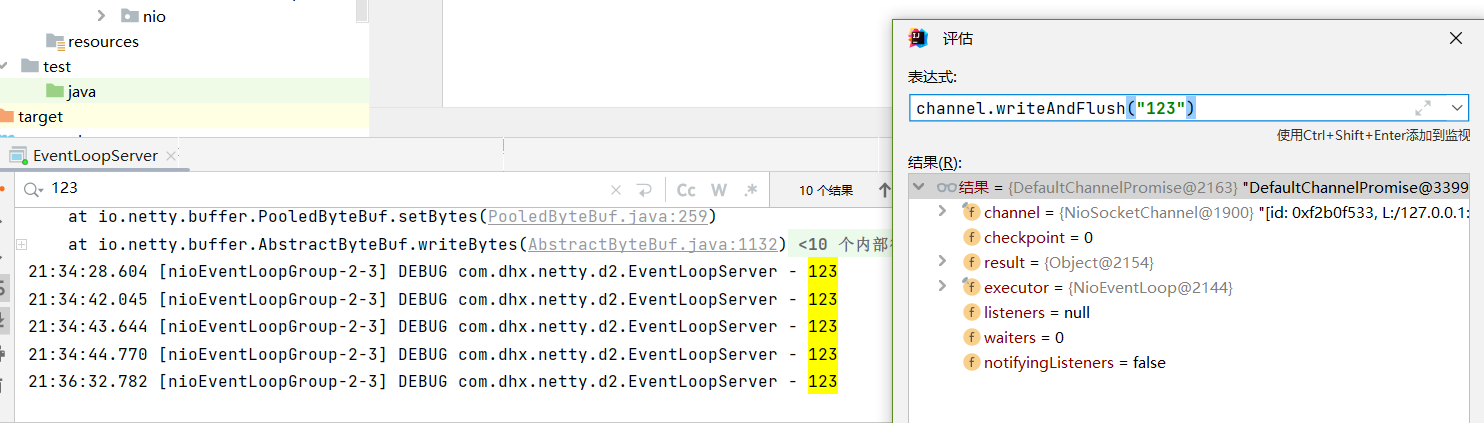
通过IDEA的评估表达式功能 发送数据
查看日志打印 , 可以看到这两个handler的执行并不是由一个线程来完成的
handler如何切换线程
下一个handler的EventLoop是否与当前的EventLoop是同一个线程
是 : 直接调用
不是 : 将要执行的代码作为任务提交给下一个EventLoop处理(换线程)
next.executor() 返回下一个EventLoopexecutor.inEventLoop() : 当前handler中的线程 , 是否和 eventLoop 是同一个线程
如果两个handler绑定的是同一个eventLoop , 那么就会直接调用
否则 , 把要调用的代码封装为一个任务对象,由下一个 handler 的线程来调用
channel
channel 的主要作用
close() 可以用来关闭 channel
closeFuture() 用来处理 channel 的关闭
sync 方法作用是同步等待 channel 关闭
而 addListener 方法是异步等待 channel 关闭
pipeline() 方法添加处理器
write() 方法将数据写入
writeAndFlush() 方法将数据写入并刷出
ChannelFuture
带有Future,Promise的类型都是和异步方法配套使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class MyClient { public static void main (String[] args) throws IOException, InterruptedException { ChannelFuture channelFuture = new Bootstrap () .group(new NioEventLoopGroup ()) .channel(NioSocketChannel.class) .handler(new ChannelInitializer <SocketChannel>() { @Override protected void initChannel (SocketChannel socketChannel) throws Exception { socketChannel.pipeline().addLast(new StringEncoder ()); } }) .connect(new InetSocketAddress ("localhost" , 8080 )); Channel channel = channelFuture.channel(); channel.writeAndFlush("hello world" ); System.in.read(); } }
如果去掉channelFuture.sync()方法,执行代码 , server无法收到Client发送的hello world
这是因为建立连接(connect)的过程是异步非阻塞 的,若不通过sync()方法阻塞主线程,等待连接真正建立,这时通过 channelFuture.channel() **拿到的 Channel 对象,并不是真正与服务器建立好连接的 Channel ( 因为此时还没有与server建立连接) **,也就没法将信息正确的传输给服务器端
因此需要通过channelFuture.sync()方法,阻塞主线程 ,同步处理结果 ,等待连接真正建立好以后,再去获得 Channel 传递数据。
使用该方法,获取 Channel 和发送数据的线程都是主线程
下面还有一种方法,用于异步 获取建立连接后的 Channel 和发送数据,使得执行这些操作的线程是 NIO 线程(去执行connect操作的线程)
addListener
通过这种方法可以在NIO线程中获取 Channel 并发送数据 ,而不是在主线程中执行这些操作
我们通过重写addListener中 operationComplete 方法 ,可以设置在client连接成功之后再进行发送数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public static void main (String[] args) throws InterruptedException { ChannelFuture channelFuture = new Bootstrap () .group(new NioEventLoopGroup ()) .channel(NioSocketChannel.class) .handler(new ChannelInitializer <Channel>() { @Override protected void initChannel (Channel channel) throws Exception { channel.pipeline().addLast(new StringEncoder ()); } }) .connect(new InetSocketAddress ("localhost" , 8080 )); channelFuture.addListener(new ChannelFutureListener () { @Override public void operationComplete (ChannelFuture future) throws Exception { Channel channel = channelFuture.channel(); log.debug(channelFuture.toString()); log.debug(future.toString()); channel.writeAndFlush("hello world" ); } }); }
close
client
不断的从控制台中读取数据发送给server
如果输入的数据为q , 那么关闭channel 退出程序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public static void main (String[] args) throws InterruptedException { ChannelFuture channelFuture = new Bootstrap () .group(new NioEventLoopGroup ()) .channel(NioSocketChannel.class) .handler(new ChannelInitializer <Channel>() { @Override protected void initChannel (Channel channel) throws Exception { channel.pipeline().addLast(new StringEncoder ()); } }) .connect(new InetSocketAddress ("localhost" , 8080 )); Channel channel = channelFuture.sync().channel(); new Thread (()->{ Scanner sc = new Scanner (System.in); while (true ){ String s = sc.nextLine(); if (s.equals("q" )){ channel.close(); break ; } channel.writeAndFlush(s); } },"input" ).start(); }
存在的问题
无法做一些关闭之后的处理操作
channel.close()方法是异步的
处理关闭的方式
同步处理关闭
异步处理关闭
Sync
1 2 3 ChanelFuture closeFuture = channel.closeFuture();closeFuture.sync(); log.debug("handle after close" );
Aysnc
1 2 3 4 5 6 7 8 9 closeFuture.addListener(new ChannelFutureListener () { @Override public void operationComplete (ChannelFuture channelFuture) throws Exception { System.out.println("关闭之后执行一些额外操作..." ); group.shutdownGracefully(); } });
Future & Promise
netty 中的 Future 与 jdk 中的 Future 同名 ,但是是两个接口
netty 的 Future 继承自 jdk 的 Future,而 Promise 又对 netty Future 进行了扩展
jdk Future 只能同步等待任务结束(或成功、或失败)才能得到结果
netty Future 可以同步等待任务结束得到结果,也可以异步方式 得到结果,但都是要等任务结束 => 提高吞吐量
netty Promise 不仅有 netty Future 的功能,而且脱离了任务独立存在,只作为两个线程间传递结果的容器
功能/名称
jdk Future
netty Future
Promise
cancel
取消任务
-
-
isCanceled
任务是否取消
-
-
isDone
任务是否完成,不能区分成功失败
-
-
get
获取任务结果,阻塞等待
-
-
getNow
-
获取任务结果,非阻塞 ,还未产生结果时返回 null
-
await
-
等待任务结束,如果任务失败,不会抛异常 ,而是通过 isSuccess 判断
-
sync
-
等待任务结束,如果任务失败,抛出异常
-
isSuccess
-
判断任务是否成功
-
cause
-
获取失败信息,非阻塞,如果没有失败,返回null
-
addLinstener
-
添加回调,异步接收结果
-
setSuccess
-
-
设置成功结果
setFailure
-
-
设置失败结果
1 2 3 4 @SuppressWarnings("ClassNameSameAsAncestorName") public interface Future <V> extends java .util.concurrent.Future<V> {}
Promise示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public static void main (String[] args) throws ExecutionException, InterruptedException { NioEventLoopGroup eventLoopGroup = new NioEventLoopGroup (3 ); EventLoop next = eventLoopGroup.next(); DefaultPromise<Integer> promise = new DefaultPromise <>(next); new Thread (()->{ log.debug("start to calculate" ); try { Thread.sleep(1000 ); } catch (InterruptedException e) { e.printStackTrace(); promise.setFailure(e); } promise.setSuccess(66 ); }).start(); System.out.println(promise.get()); }
Handler & PipeIine
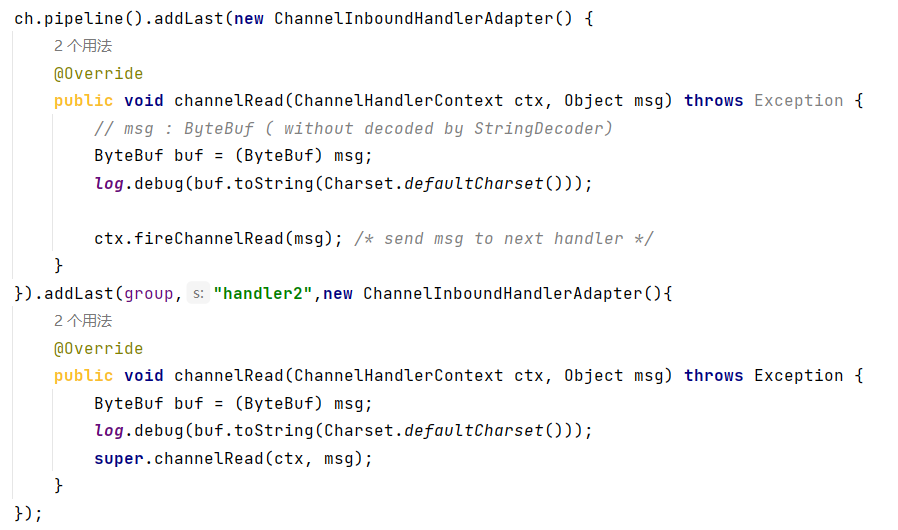
通过channel.pipeline().addLast(name, handler)添加handler时,记得给handler取名字 。这样可以调用pipeline的addAfter()、addBefore()等方法更灵活地向pipeline中添加handler
handler需要放入通道的pipeline中,才能根据放入顺序来使用handler
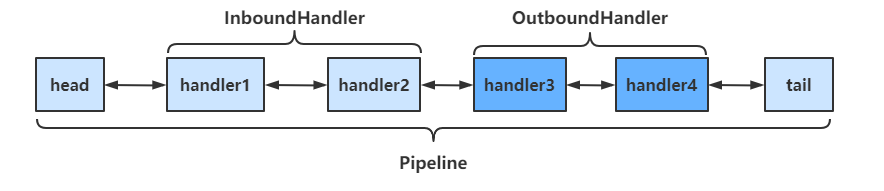
pipeline是结构是一个带有head与tail指针的双向链表 ,其中的节点为handler
要通过ctx.fireChannelRead(msg)等方法,将当前handler的处理结果传递给下一个handler
当有入栈 (Inbound)操作时,会从head开始向后 调用handler,直到handler不是处理Inbound操作为止
当有出栈 (Outbound)操作时,会从tail开始向前 调用handler,直到handler不是处理Outbound操作为止
具体结构如下
调用顺序如下
server
在server我们定义了三个inboundPipeline以及三个outboundPipeline
通过client发送数据 , 代码执行结果
1 2 3 4 5 6 7 8 16:37:31.078 [nioEventLoopGroup-2-2] DEBUG com.dhx.netty.d3.TestPipeline - 1 16:37:31.078 [nioEventLoopGroup-2-2] DEBUG com.dhx.netty.d3.TestPipeline - 2 16:37:31.078 [nioEventLoopGroup-2-2] DEBUG com.dhx.netty.d3.TestPipeline - 3 16:37:31.078 [nioEventLoopGroup-2-2] DEBUG io.netty.channel.DefaultChannelPipeline - Discarded inbound message PooledUnsafeDirectByteBuf(ridx: 0, widx: 1, cap: 2048) that reached at the tail of the pipeline. Please check your pipeline configuration. 16:37:31.088 [nioEventLoopGroup-2-2] DEBUG io.netty.channel.DefaultChannelPipeline - Discarded message pipeline : [handler1, handler2, handler3, handler4, handler5, handler6, DefaultChannelPipeline$TailContext#0]. Channel : [id: 0x0e3cacda, L:/127.0.0.1:8080 - R:/127.0.0.1:1268]. 16:37:31.089 [nioEventLoopGroup-2-2] DEBUG com.dhx.netty.d3.TestPipeline - 6 16:37:31.089 [nioEventLoopGroup-2-2] DEBUG com.dhx.netty.d3.TestPipeline - 5 16:37:31.089 [nioEventLoopGroup-2-2] DEBUG com.dhx.netty.d3.TestPipeline - 4
super.channelRead(ctx, msg);实际上承担了在 pipeline之间传输数据的工作( 类似于过滤器 , 需要连接起来才能正常工作 )
源码如下
1 2 3 4 5 @Skip @Override public void channelRead (ChannelHandlerContext ctx, Object msg) throws Exception { ctx.fireChannelRead(msg); }
关于OutboundHandler
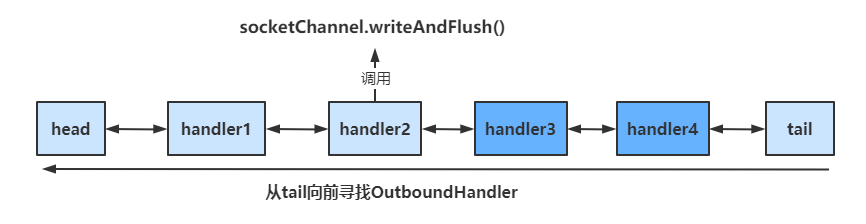
socketChannel.writeAndFlush()
当handler中调用该方法进行写操作时,会触发Outbound操作,此时是从tail向前寻找OutboundHandler
ctx.writeAndFlush()
当handler中调用该方法进行写操作时,会触发Outbound操作,此时是从当前handler向前寻找OutboundHandler
EmbeddedChannel- 测试Handler
EmbeddedChannel可以用于测试各个handler,通过其构造函数按顺序传入需要测试handler,然后调用对应的Inbound和Outbound方法即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 @Slf4j public class EmbeddedChannelTest { public static void main (String[] args) { ChannelInboundHandlerAdapter h1 = new ChannelInboundHandlerAdapter () { @Override public void channelRead (ChannelHandlerContext ctx, Object msg) throws Exception { log.debug("1" ); super .channelRead(ctx, msg); } }; ChannelInboundHandlerAdapter h2 = new ChannelInboundHandlerAdapter () { @Override public void channelRead (ChannelHandlerContext ctx, Object msg) throws Exception { log.debug("2" ); super .channelRead(ctx, msg); } }; ChannelOutboundHandlerAdapter h3 = new ChannelOutboundHandlerAdapter () { @Override public void write (ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception { log.debug("3" ); super .write(ctx, msg, promise); } }; ChannelOutboundHandlerAdapter h4 = new ChannelOutboundHandlerAdapter () { @Override public void write (ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception { log.debug("4" ); super .write(ctx, msg, promise); } }; EmbeddedChannel channel = new EmbeddedChannel (h1, h2, h3, h4); channel.writeInbound(ByteBufAllocator.DEFAULT.buffer().writeBytes("adorabled4" .getBytes(StandardCharsets.UTF_8))); channel.writeOutbound(ByteBufAllocator.DEFAULT.buffer().writeBytes("adorabled4" .getBytes(StandardCharsets.UTF_8))); } }
ByteBuf
ByteBuf可以自动扩容( 翻倍 ) , 初始容量为256
ByteBuf buf = ByteBufAllocator.DEFAULT.buffer()
io.netty.buffer.AbstractByteBufAllocator
1 2 3 4 5 6 7 public abstract class AbstractByteBufAllocator implements ByteBufAllocator { static final int DEFAULT_INITIAL_CAPACITY = 256 ; static final int DEFAULT_MAX_CAPACITY = Integer.MAX_VALUE; static final int DEFAULT_MAX_COMPONENTS = 16 ; static final int CALCULATE_THRESHOLD = 1048576 * 4 ; }
关于扩容
1 2 3 4 5 6 public static void main (String[] args) { ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(); System.out.println(buffer); buffer.writeBytes("a" .repeat(257 ).getBytes()); System.out.println(buffer); }
打印结果为 :
PooledUnsafeDirectByteBuf(ridx: 0, widx: 0, cap: 256)PooledUnsafeDirectByteBuf(ridx: 0, widx: 257, cap: 512)
创建
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Slf4j public class ByteBufTest1 { public static void main (String[] args) { ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(16 ); buffer.writeBytes("a" .repeat(32 ).getBytes()); log(buffer); } private static void log (ByteBuf buffer) { int length = buffer.readableBytes(); int rows = length / 16 + (length % 15 == 0 ? 0 : 1 ) + 4 ; StringBuilder buf = new StringBuilder (rows * 80 * 2 ) .append("read index:" ).append(buffer.readerIndex()) .append(" write index:" ).append(buffer.writerIndex()) .append(" capacity:" ).append(buffer.capacity()) .append(NEWLINE); appendPrettyHexDump(buf, buffer); System.out.println(buf.toString()); } }
运行结果
1 2 3 4 5 6 7 read index:0 write index:32 capacity:64 +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f | +--------+-------------------------------------------------+----------------+ |00000000| 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 |aaaaaaaaaaaaaaaa| |00000010| 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 |aaaaaaaaaaaaaaaa| +--------+-------------------------------------------------+----------------+
ByteBuf通过ByteBufAllocator选择allocator并调用对应的buffer()方法来创建的 ,默认使用直接内存 作为ByteBuf,容量为256个字节,可以指定初始容量的大小
当ByteBuf的容量无法容纳所有数据时,ByteBuf会进行扩容操作
实际上是ByteBuf在写入之前会预先确定是否可以写入的
io.netty.buffer.AbstractByteBuf#writeBytes(byte[], int, int)
1 2 3 4 5 6 public ByteBuf writeBytes (byte [] src, int srcIndex, int length) { ensureWritable(length); setBytes(writerIndex, src, srcIndex, length); writerIndex += length; return this ; }
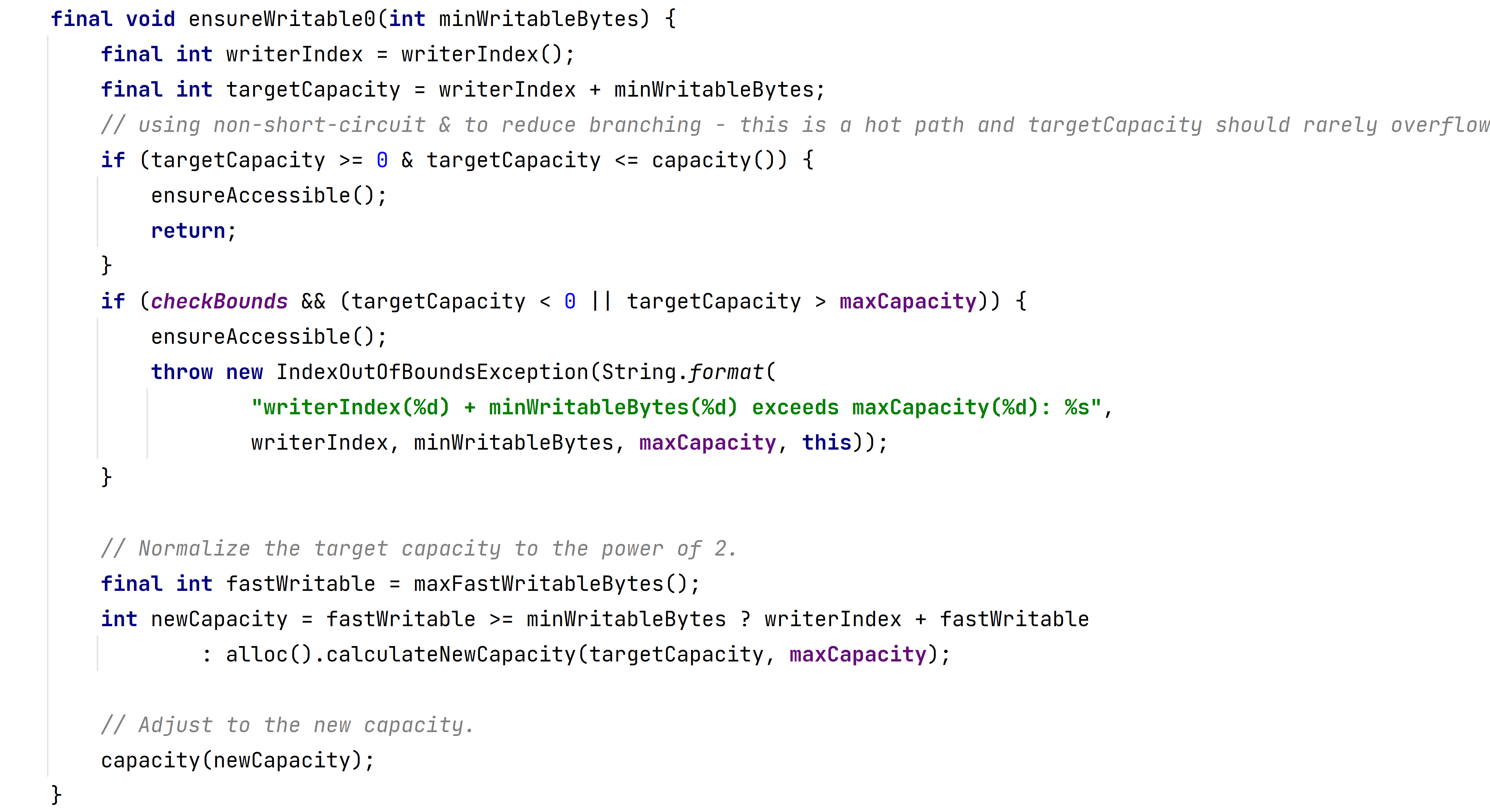
扩容操作在 ensureWritable() 方法中进行
注释版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 final void ensureWritable0 (int minWritableBytes) { final int writerIndex = writerIndex(); final int targetCapacity = writerIndex + minWritableBytes; if (targetCapacity >= 0 & targetCapacity <= capacity()) { ensureAccessible(); return ; } if (checkBounds && (targetCapacity < 0 || targetCapacity > maxCapacity)) { ensureAccessible(); throw new IndexOutOfBoundsException (String.format( "writerIndex(%d) + minWritableBytes(%d) 超出了 maxCapacity(%d): %s" , writerIndex, minWritableBytes, maxCapacity, this )); } final int fastWritable = maxFastWritableBytes(); int newCapacity = fastWritable >= minWritableBytes ? writerIndex + fastWritable : alloc().calculateNewCapacity(targetCapacity, maxCapacity); capacity(newCapacity); }
如果在handler中创建ByteBuf,建议使用ChannelHandlerContext ctx.alloc().buffer()来创建
直接内存与堆内存
通过该方法创建的ByteBuf,使用的是基于直接内存 的ByteBuf
1 ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(16);Copy
可以使用下面的代码来创建池化基于堆 的 ByteBuf
1 ByteBuf buffer = ByteBufAllocator.DEFAULT.heapBuffer(16);Copy
也可以使用下面的代码来创建池化基于直接内存 的 ByteBuf
1 ByteBuf buffer = ByteBufAllocator.DEFAULT.directBuffer(16);Copy
直接内存创建和销毁的代价昂贵,但读写性能高(少一次内存复制),适合配合池化功能一起用
直接内存对 GC 压力小,因为这部分内存不受 JVM 垃圾回收的管理,但也要注意及时主动释放
池化与非池化
池化的最大意义在于可以重用 ByteBuf,优点有
没有池化,则每次都得创建新的 ByteBuf 实例,这个操作对直接内存代价昂贵,就算是堆内存,也会增加 GC 压力
有了池化,则可以重用池中 ByteBuf 实例,并且采用了与 jemalloc 类似的内存分配算法提升分配效率
高并发时,池化功能更节约内存,减少内存溢出的可能
池化功能是否开启,可以通过下面的系统环境变量来设置
1 -Dio.netty.allocator.type={unpooled|pooled}Copy
4.1 以后,非 Android 平台默认启用池化实现 ,Android 平台启用非池化实现
4.1 之前,池化功能还不成熟,默认是非池化实现
通过buf.getClass() 即可查看buf创建的实际类型, 来确定是否池化
1 2 3 4 5 6 7 8 9 public static void main (String[] args) { ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(16 ); buffer.writeBytes("a" .repeat(32 ).getBytes()); System.out.println(buffer.getClass()); } class io .netty.buffer.PooledUnsafeDirectByteBuf
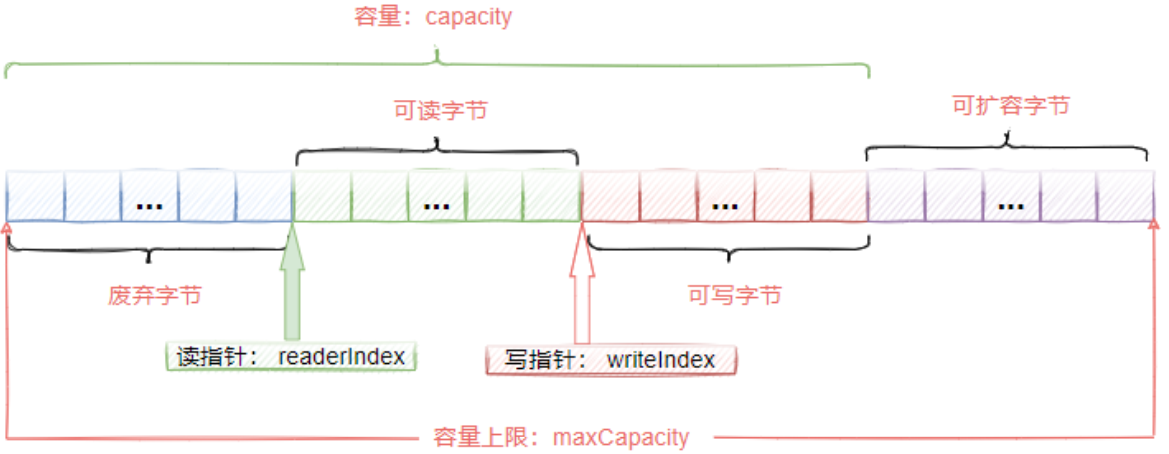
组成
ByteBuf主要有以下几个组成部分
写入
常用方法如下
方法签名
含义
备注
writeBoolean(boolean value)
写入 boolean 值
用一字节 01|00 代表 true|false
writeByte(int value)
写入 byte 值
writeShort(int value)
写入 short 值
writeInt(int value)
写入 int 值
Big Endian(大端写入 ),即 0x250,写入后 00 00 02 50
writeIntLE(int value)
写入 int 值
Little Endian(小端写入),即 0x250,写入后 50 02 00 00
writeLong(long value)
写入 long 值
writeChar(int value)
写入 char 值
writeFloat(float value)
写入 float 值
writeDouble(double value)
写入 double 值
writeBytes(ByteBuf src)
写入 netty 的 ByteBuf
writeBytes(byte[] src)
写入 byte[]
writeBytes(ByteBuffer src)
写入 nio 的 ByteBuffer
int writeCharSequence(CharSequence sequence, Charset charset)
写入字符串
CharSequence为字符串类的父类 ,第二个参数为对应的字符集
注意
这些方法的未指明返回值的,其返回值都是 ByteBuf,意味着可以链式调用来写入不同的数据
网络传输中,默认习惯是 Big Endian ,使用 writeInt(int value)
读取
读取主要是通过一系列read方法进行读取,读取时会根据读取数据的字节数移动读指针
如果需要重复读取 ,需要调用buffer.markReaderIndex()对读指针进行标记,并通过buffer.resetReaderIndex()将读指针恢复到mark标记的位置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class ByteBufStudy { public static void main (String[] args) { ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(16 , 20 ); buffer.writeBytes(new byte []{1 , 2 , 3 , 4 }); buffer.writeInt(5 ); System.out.println(buffer.readByte()); System.out.println(buffer.readByte()); System.out.println(buffer.readByte()); System.out.println(buffer.readByte()); ByteBufUtil.log(buffer); buffer.markReaderIndex(); System.out.println(buffer.readInt()); ByteBufUtil.log(buffer); buffer.resetReaderIndex(); ByteBufUtil.log(buffer); } }
运行结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 1 2 3 4 read index:4 write index:8 capacity:16 +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f | +--------+-------------------------------------------------+----------------+ |00000000 | 00 00 00 05 |.... | +--------+-------------------------------------------------+----------------+ 5 read index:8 write index:8 capacity:16 read index:4 write index:8 capacity:16 +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f | +--------+-------------------------------------------------+----------------+ |00000000 | 00 00 00 05 |.... | +--------+-------------------------------------------------+----------------+Copy
以 get 开头的一系列方法,这些方法不会改变读指针的位置
释放
由于 Netty 中有堆外内存(直接内存)的 ByteBuf 实现,堆外内存最好是手动来释放 ,而不是等 GC 垃圾回收。
UnpooledHeapByteBuf 使用的是 JVM 内存,只需等 GC 回收内存即可UnpooledDirectByteBuf 使用的就是直接内存了,需要特殊的方法来回收内存PooledByteBuf 和它的子类使用了池化机制 ,需要更复杂的规则来回收内存
Netty 这里采用了引用计数法 来控制回收内存,每个 ByteBuf 都实现了 ReferenceCounted 接口
每个 ByteBuf 对象的初始计数 为 1
调用 release 方法计数减 1,如果计数为 0,ByteBuf 内存被回收
调用 retain 方法计数加 1,表示调用者没用完之前,其它 handler 即使调用了 release 也不会造成回收
当计数为 0 时,底层内存会被回收,这时即使 ByteBuf 对象还在,其各个方法均无法正常使用(内存都没了显然没法用)
释放规则
因为 pipeline 的存在,一般需要将 ByteBuf 传递给下一个 ChannelHandler,如果在每个 ChannelHandler 中都去调用 release ,就失去了传递性 (如果在这个 ChannelHandler 内这个 ByteBuf 已完成了它的使命,那么便无须再传递)
基本规则是,谁是最后使用者,谁负责 release
当ByteBuf被传到了pipeline的head与tail时 ,ByteBuf会被其中的方法彻底释放,但前提是ByteBuf被传递到了head与tail中
TailConext中释放ByteBuf的源码
1 2 3 4 5 6 7 8 protected void onUnhandledInboundMessage (Object msg) { try { logger.debug("Discarded inbound message {} that reached at the tail of the pipeline. Please check your pipeline configuration." , msg); } finally { ReferenceCountUtil.release(msg); } }
判断传过来的是否为ByteBuf,是的话才需要释放
1 2 3 public static boolean release (Object msg) { return msg instanceof ReferenceCounted ? ((ReferenceCounted)msg).release() : false ; }
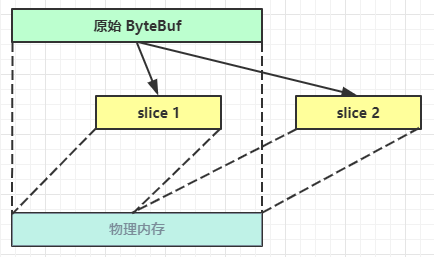
切片
retain vt. 保持;保留;持有;聘请(律师等);继续拥有;继续容纳
ByteBuf切片是【零拷贝】的体现之一,对原始 ByteBuf 进行切片成多个 ByteBuf,切片后的 ByteBuf 并没有发生内存复制,还是使用原始 ByteBuf 的内存 ,切片后的 ByteBuf 维护独立的 read,write 指针
得到分片后的buffer后,要调用其retain方法,使其内部的引用计数加一。避免原ByteBuf释放,导致切片buffer无法使用
修改原ByteBuf中的值,也会影响切片后得到的ByteBuf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public class SliceTest { public static void main (String[] args) { ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(16 , 20 ); buffer.writeBytes(new byte []{1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 }); ByteBuf slice1 = buffer.slice(0 , 5 ); ByteBuf slice2 = buffer.slice(5 , 5 ); slice1.retain(); slice2.retain(); log(slice1); log(slice2); System.out.println("===========modify original buffer===========" ); buffer.setByte(0 , 5 ); System.out.println("===========print slice1===========" ); log(slice1); } private static void log (ByteBuf buffer) { int length = buffer.readableBytes(); int rows = length / 16 + (length % 15 == 0 ? 0 : 1 ) + 4 ; StringBuilder buf = new StringBuilder (rows * 80 * 2 ) .append("read index:" ).append(buffer.readerIndex()) .append(" write index:" ).append(buffer.writerIndex()) .append(" capacity:" ).append(buffer.capacity()) .append(NEWLINE); appendPrettyHexDump(buf, buffer); System.out.println(buf.toString()); } }
运行结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 read index:0 write index:5 capacity:5 +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f | +--------+-------------------------------------------------+----------------+ |00000000| 01 02 03 04 05 |..... | +--------+-------------------------------------------------+----------------+ read index:0 write index:5 capacity:5 +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f | +--------+-------------------------------------------------+----------------+ |00000000| 06 07 08 09 0a |..... | +--------+-------------------------------------------------+----------------+ ===========modify original buffer=========== ===========print slice1=========== read index:0 write index:5 capacity:5 +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f | +--------+-------------------------------------------------+----------------+ |00000000| 05 02 03 04 05 |..... | +--------+-------------------------------------------------+----------------+
零拷贝
CompositeByteBuf : 复合字节Buf
注意需要使用 addComponent()方法
避免了内存的复制 , 但是需要同时维护多块内存的读写指针, 也带来了重复的计算。
示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 public static void main (String[] args) { ByteBuf buf1 = ByteBufAllocator.DEFAULT.buffer().writeBytes(new byte []{1 , 2 , 3 , 4 , 5 }); ByteBuf buf2 = ByteBufAllocator.DEFAULT.buffer().writeBytes(new byte []{6 ,7 ,8 ,9 ,10 }); ByteBuf byteBuf = ByteBufAllocator.DEFAULT.buffer().writeBytes(buf1).writeBytes(buf2); System.out.println(byteBuf); CompositeByteBuf compositeBuffer = ByteBufAllocator.DEFAULT.compositeBuffer(); compositeBuffer.addComponent(buf1).addComponent(buf2); System.out.println(compositeBuffer); }
debug运行程序 , 可以看到实际上compositeBuffer数据的地址就是前面buf1 以及 buf2 的地址。
compositeBuffer由于内部是使用的同一块内存 , 因此也需要注意引用计数的问题
使用compostiteBuffer.retain()来保持住引用的内存( 实质是引用计数器+1)
这里的引用计数器使用的范围很广 , UNIX操作系统文件的i节点也是同样的原理
ByteBuf优点
池化思想 - 可以重用池中 ByteBuf 实例,更节约内存,减少内存溢出的可能
读写指针分离 ,不需要像 ByteBuffer 一样切换读写模式可以自动扩容
支持链式调用,使用更流畅
很多地方体现零拷贝
slice、duplicate、CompositeByteBuf使用零拷贝一定不能忽视引用计数器的问题!
参考










 ]
]