
GFS(Google File System)论文解读
The Google file system 论文首次发布与2003年的SOSP会议上
关于SOSP
按照USnews的分类,Computer Science被分为四个大类:AI, Programming Language, Systems, Theory。毫无疑问,Systems是这四个大类中最要紧也是最大的一个。
SOSP是一个相对古老的会议,它是由ACM下属的SIGOPS (the ACM Special Interest Group on Operating Systems)于1967年创办的。会议两年一次,,每届收录的文章在20篇左右。
SOSP与OSDI是OS最好的会议,每两年开一次轮流开,比如今年是OSDI,那么明年就是SOSP。由于这两个会议方向很广,因此影响很大。
GFS主要解决的问题就是大型存储(分布式存储)的问题 。
在分布式系统中,可能有各种各样重要的抽象可以应用在分布式系统中,但实际上简单的存储接口往往非常有用且极其通用。
因此构建分布式系统大多都是关于如何设计存储系统,或是设计其它基于大型分布式存储的系统。
所以我们更加关注如何为大型分布式存储系统设计一个优秀的接口,以及如何设计存储系统的内部结构,这样系统才能良好运行。
Get Started
问题引入
设计分布式系统或者是大型存储系统的出发点往往是 获取更强的性能 。单台计算机的性能始终是有限的,通过利用多台计算机的资源来构建分布式系统可以来完成更多的工作。
例如目前服务器单台的硬盘容量能达到TB量级,但是数据的量级往往会更高,并且数据是在不断增长的。这里很容易就联想到把数据切分成多个切片(pieces) , 然后放到不同的计算机上面去存储,在读取的时候从多台计算机中去读取数据。
The largest cluster to date provides hun- dreds of terabytes of storage across thousands of disks on over a thousand machines, and it is concurrently accessed by hundreds of clients.
GFS由数百甚至数千台存储机器组成,这些存储机器由廉价的商品部件组装而成,并由大量的客户机访问。
在这些计算机中出现故障是非常常见的, 组件的数量和质量实际上保证了某些组件在任何给定的时间都不能正常工作,而有些组件无法从当前的故障中恢复。
可能引发故障的因素有很多, 比如应用程序bug、操作系统bug、人为错误以及磁盘、内存、连接器、网络和电源故障引起的问题。
因此,持续的监控、错误检测、容错和自动恢复必须成为系统不可或缺的一部分。
这里几个关键词英语要知道 Constant monitoring, Error detection, Fault tolerance, Consistency , Replication
由于故障非常常见, 因此自动化的解决办法是十分有必要的,这里引入了 Fault tolerance(容错系统)的问题
实现容错最简单的方法就是通过复制(Replication),通过复制一份数据的两到三个副本(副本一般情况下位于不同的计算机中)就可以达到不错的状态。
即便其中的一个副本(可能是计算机,也可能是文件)出现了问题,通过剩余的副本也可以保证顺利完成工作。
那么由于引入了副本,就不得不考虑到**数据一致性(Consistency)**的问题 , 假如其中的一份副本的数据修改了, 但是别的副本的数据没有及时的完成数据的统一, 对于客户端来说就很有可能读取到不一样的数据(旧的数据新的数据都有可能, 这取决于Master如何分配)。
为了解决数据一致性的问题,总会需要进行额外的工作,这种操作(分布式系统往往通过网络)往往会降低性能,这似乎与起点冲突。
Architecture
GFS的场景
-
廉价的商用计算机 : 系统必须不断地监控自己 , 并且能够检测, 容忍和迅速从组件故障中恢复
-
较大文件: 文件数量很多并且每个文件的大小通常大于100MB , 不过GFS同样支持小文件。
在存储系统中有一个完全不同的领域,这个领域只对小份数据进行优化。例如一个银行账户系统就需要一个能够读写100字节的数据库,因为100字节就可以表示人们的银行账户。
-
工作负载: 大的流读取以及小的随机读取, 两者常见的单个操作的数据量级分别为1MB以及 kb
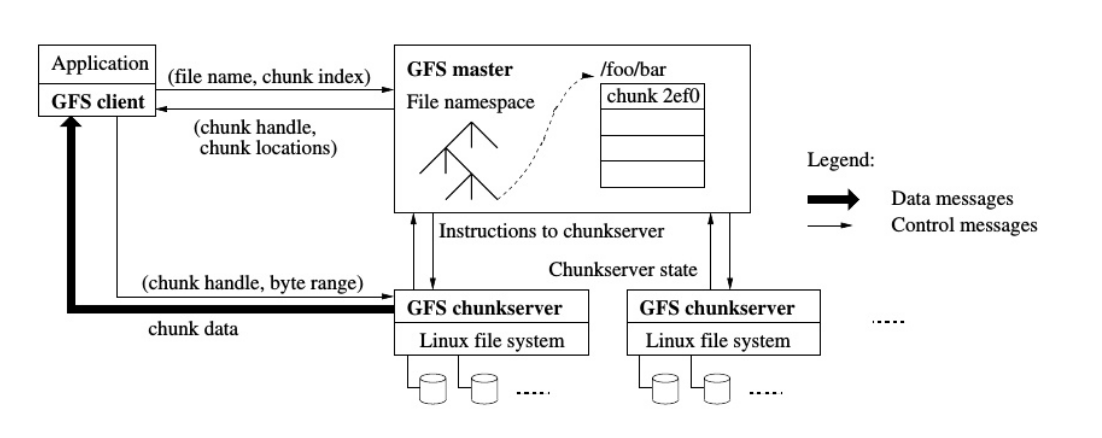
GFS cluster主要由单个的Master服务器以及众多的chunk服务器构成,服务器通常为普通的Linux服务器。
由于Master服务器只有一个, 因此性能问题对于Master十分重要 , 后面的大多设计都可以发现GFS非常注重减小Master的压力
关于 ‘块’ 与Metadata
对于普通的Linux服务器, 文件数据都存储在Block(一般为4KB)中,文件的元数据(比如文件名,创建时间,所有者,文件大小等)存储在i节点中。
对于HDD, 最小的存储单位为扇区(Sector) , 一个扇区的大小为 0.5kb , 不过由于如今的文件越来越大, OS在读取硬盘的时候不会以扇区为单位进行读取 , 而是一次性读取多个连续的扇区(一个Block) , 同样的, Block是文件存取的最小单位, win10中块的大小为4kB。
- 比如下图中文件的实际数据大小只有2.26KB, 但占用空间为4KB

对于GFS, 一个块的大小为64MB , 并且每个块的duplication 会以 普通Linux文件 的形式存储在chunkserver中。
较大的块主要有以下的几个优点
- 对于同一个块的读写只需要向Master发送一次读写请求(试想如果请求过多单台的Master有可能非常容易出现故障)就可以得到chunk的信息
- 大大减小了元数据的大小(同上 , 可以减轻Master的压力 , 因为元数据信息保存在Master的内存中, 考虑到内存的容量并不大)
- 文件块较大 , 客户端可以在一个块上就完成自己需要的操作 (不需要多次更新操作的块, 因为这需要请求Master , 这样一来可以减小网络开销)
这一部分中论文中提到了
Each chunk replica is stored as a plain Linux file on a chunkserver and is extended only as needed.
Lazy space allocation avoids wasting space due to internal fragmentation, perhaps the greatest objection against such a large chunk size.每个块副本以普通Linux文件的形式存储在chunkserver上,仅在需要时进行扩展。惰性空间分配避免了由于内部碎片而造成的空间浪费,这可能是反对如此大的块大小的最大原因。
这里 Lazy space allocation 翻译成 延迟分配 我想会更好理解 , 与 单例模式的懒汉式实现方法类似 , 延迟分配指的是在需要使用到chunk的数据的时候再去分配文件块
Java懒汉式单例模式实现
2
3
4
5
6
7
8
9
10
11
public static Instance instance;
public static Instance getInstance(){
synchronized{
if(instance == null){
instance = new Instance();
}
return instance;
}
}
}
master会存储三种主要类型的元数据: 文件和 块命名空间,文件到块的映射,以及每个块的副本的位置。
其中所有的元数据都会保存在Master的内存中, 同时Master也会通过(存储 日志变更 和 操作日志到master的本地磁盘中)以及(在远程机器中重复 : replicated on remote machines ) 来持久化 名称-空间和 文件-块映射
Master为每个64MB的块维护少于64B的元数据。
具体的来讲 , 两个映射关系细节如下
- 第一个是文件名到chunk ID或者chunk Handle数组的对应。这个包含文件对应了哪些chunk。也就是
file: list<chunkId>。 - 第二个表单记录了chunk ID到chunk数据的对应关系。这里的数据又包括了:
- 每个chunk存储在哪些服务器上,所以这部分是chunkserver的列表
- 每个chunk当前的版本号,所以Master节点必须记住每个chunk对应的版本号。
- Primary chunk的信息(例如服务器地址)
- Primary chunk的租约过期时间。
关于租约 会在后面提到 , 这里知道即可。
一般来说 , 大多数块都是满的,因为大多数文件包含许多块,只有最后一个块可能被部分填充。
Master会在启动的时候轮询 chunkserver来获取 chunkserver与 duplication 对应的信息 。
操作日志
操作日至记录关键元数据变更的记录。
由于 在操作文件信息之前 客户端都需要通过Master来获取到文件对应的位置 , 因此确保Master中元数据的准确性极其重要
假如操作日志不准确, 导致元数据不准确 , 即便某个 chunk实际存在 , Master却不知道 , 实际上也相当于数据丢失
Master会通过操作日志来执行相关的恢复操作,在元数据更改被持久化到Master以及远程服务器之前 , 操作对于客户端是不可见的(保证consistency), 只有Master Local以及远程服务器刷新日志到磁盘之后才会响应客户端的操作。
这样一来不可避免的就会导致操作日志会非常庞大, GFS的做法是Master在磁盘中创建一些checkPoint点 ,
当下一次Master重启的时候会从latest checkpoint开始恢复 。
通过上面基本了解GFS ,这里不按照论文的顺序 ,分别从实际的应用(读写文件中来介绍GFS的重点内容)
Read
获取chunk server
对于读请求 , 客户端的应用程序(向Master)发送请求,携带一个文件名以及文件的某个读取位置的偏移量
1 | { |
Master节点会从自己的file 表单中查询文件名,得到chunkID的数组。因为每个chunk是64MB,所以偏移量除以64MB就可以从数组中得到对应的chunkID。
之后Master再从chunk表单中找到存有chunk的服务器列表,并将列表返回给客户端。
**总结就是: **
- 客户端(或者应用程序)将文件名和偏移量发送给Master。
- Master节点将chunk Handle(也就是ID,记为H)和服务器列表发送给客户端。
客户端可以从这些chunk server中挑选一个来读取数据。
GFS中客户端会选择一个网络上最近的chunk server , 并将读请求发送到那个服务器。
因为客户端每次可能只读取1MB或者64KB数据,所以,客户端可能会连续多次读取同一个chunk的不同位置。所以,客户端会缓存chunk和服务器的对应关系,这样,当再次读取相同chunk数据时,就不用一次次的去向Master请求相同的信息。
Google的数据中心IP地址是连续的,所以可以从IP地址的差异判断网络位置的远近
网络位置的远近并不等价于地理位置 , 由于网络数据在链路中传输 , 往往会经过许多的交换机以及路由器 , 这是实际需要考虑的网络距离
读取数据
接着客户端可以选择一个chunk server进行通信(获取数据) , 并且把chunk Handle和偏移量发送给那个chunk server
chunk服务器会在本地的硬盘上,将每个chunk存储成独立的Linux文件,并通过普通的Linux文件系统进行管理。
chunk server需要做的就是根据文件名找到对应的chunk文件,之后从文件中读取对应的数据段,并将数据返回给客户端。
关于 consistency
对于每一个chunk来讲, 它们都是副本。实际上,不同chunk服务器上的数据并不一定完全相同。
应用程序应该要能够容忍这种情况。所以实际上如果从不同的chunk服务器读取数据,可能会略微不同。
GFS论文提到客户端会尝试从同一个机架或者同一个交换机上的服务器读取数据。
Write
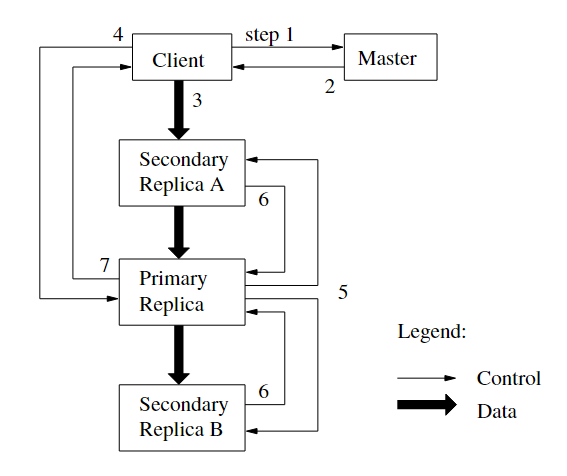
对于读文件来来说 , 客户端可以读取任何一个副本的数据 , 但是对于写文件, 只能通过主副本 (Primary chunk)来写入
- 客户端向 Master 请求该 chunk 的 Lease(询问Primary chunk)
- Master 向客户端返回 Primary 和secondary chunk 的位置信息
- 客户端将数据发送到所有的 chunk 上。chunk Server 会把这些数据保存在缓冲区中,等待使用
- 待所有 chunk 都接收到数据后,客户端发送写请求给 Primary。Primary 为来自各个客户端的修改操作安排连续的执行序列号,并按顺序地应用于其本地存储的数据
- Primary 将写请求转发给其他 Secondary chunk ,chunk 们按照相同的顺序应用这些修改
- Secondary chunk 响应 Primary,示意自己已经完成操作
- Primary 响应客户端,并返回该过程中发生的错误(假如发生了的话)
假如Primary chunk不存在?
对于某个特定的chunk来说,在某一个时间点Master不一定指定了chunk的主副本。
所以,写文件的时候,需要考虑chunk的主副本不存在的情况。
对于Master节点来说,如果发现chunk的主副本不存在,Master会找出所有存有chunk最新副本的chunk服务器。
如果一个系统已经运行了很长时间,那么有可能某一个chunk服务器保存的chunk副本是旧的,比如说还是昨天或者上周的。导致这个现象的原因可能是服务器因为宕机而没有收到任何的更新。所以,Master节点需要能够在chunk的多个副本中识别出,哪些副本是新的,哪些是旧的。
所以首先是找出最新的chunk副本。这一切都是在Master节点发生,因为是客户端告诉Master节点说要追加某个文件,Master节点需要告诉客户端向哪个chunk服务器(也就是Primary chunk所在的服务器)去做追加操作。所以,Master节点的部分工作就是弄清楚在追加文件时,客户端应该与哪个chunk服务器通信。
每个chunk可能同时有多个版本的副本,最新的副本是指副本中保存的版本号与Master中记录的chunk的版本号一致。
chunk副本中的版本号是由Master节点下发的(并且会持久化在lcoal Disk 以及 remote machine),所以Master节点知道对于每一个chunk,哪个版本号是最新的。
这就是为什么chunk的版本号在Master节点上需要保存在磁盘这种非易失的存储中的原因,因为如果版本号在故障重启中丢失,且部分chunk服务器持有旧的chunk副本,这时,Master是没有办法区分哪个chunk服务器的数据是旧的,哪个chunk服务器的数据是最新的。
6.824中提问
为什么不使用最大的版本号作为最新的版本号?
当Master重启时,确定哪个chunk服务器与chunk的映射关系 , 需要与所有的chunk服务器进行通信 , Master可以将所有chunk服务器上的chunk版本号汇总,找出里面的最大值作为最新的版本号。如果所有持有chunk的服务器都响应了,那么这种方法是没有问题的。但是存在一种风险,**当Master节点重启时,可能部分chunk服务器离线或者失联或者自己也在重启,从而不能响应Master节点的请求。**所以,Master节点可能只能获取到持有旧副本的chunk服务器的响应,而持有最新副本的chunk服务器还没有完成重启,或者还是离线状态(这个时候Master能找到的chunk最大版本明显不对)
当Master找不到持有最新chunk的服务器时该怎么办?
Master节点会定期与chunk服务器交互来查询它们持有什么样版本的chunk。假设Master保存的chunk版本是17,但是又没有找到版本号是17的chunk服务器,
那么有两种可能:
- Master会等待,并不响应客户端的请求;
- 返回给客户端,目前无法找到chunk, 请过会重试。比如说机房电源故障了,所有的服务器都崩溃了,我们正在缓慢的重启。Master节点和一些chunk服务器可能可以先启动起来,一些chunk服务器可能要5分钟以后才能重启,这种场景下,我们需要等待,甚至可能是永远等待,因为你不会想使用chunk的旧数据。
如果chunk服务器上报的版本号高于Master存储的版本号会怎么样?
GFS论文说,如果Master节点重启,并且与chunk服务器交互,同时一个chunk服务器重启,并上报了一个比Master记住的版本更高的版本。Master会认为它在分配新的Primary服务器时出现了错误,并且会使用这个更高的版本号来作为chunk的最新版本号。
当Master向Primary和Secondary发送完消息之后就崩溃了,可能会出现上面这种情况。为了让Master能够处理这种情况,Master在发送完消息之后,需要将chunk的最新版本写入到磁盘中。这里的写入或许需要等到Primary和Secondary返回确认消息之后。
- 如果此时确实找不到对应的chunk的位置 , 那么Master会从所有的最新版本的chunk中挑选一个作为 Primary chunk , 其他的作为secondary chunk。
- Master会增加版本号(同时持久化到local Disk , 对应前面提到的持久化元数据的内容 )
- 在持久化日志变更和操作记录完成之后 , Master会通知 副本对应的服务器 更新的内容 (比如谁是Primary,谁是Secondary,chunk的新版本是什么)
或许2 3 的顺序并不绝对 , 论文中并未提到
关于Primary chunk 的"租约"
在更新了Primary chunk之后, Master通知Primary和Secondary服务器,你们可以修改这个chunk。
Master还给Primary一个租约,这个租约告诉Primary说,在接下来的60秒中,你将是Primary,60秒之后你必须停止成为Primary。这种机制可以确保(对于某一个chunk的所有副本)不会同时有两个Primary。
为什么需要租约机制?
我们假设在某个时间点,Master指定了一个Primary,之后Master会一直通过定期的ping来检查它是否还存活。
Master发送了一些ping给Primary,并且Primary没有回应,但是Master并不会在那个时间立刻指定一个新的Primary。
假如网络的原因导致ping没有成功,那么有可能Primary还活着,但是网络的原因导致ping失败了。但同时,Primary还可以与客户端交互,如果Master为chunk指定了一个新的Primary,那么就会同时有两个Primary处理写请求,这两个Primary不知道彼此的存在,会分别处理不同的写请求,最终会导致有两个不同的数据拷贝。这被称为脑裂(split-brain)。
脑裂通常是由网络分区引起的。比如说,Master无法与Primary通信,但是Primary又可以与客户端通信,这就是一种网络分区问题。网络故障是这类分布式存储系统中最难处理的问题之一。
所以在上面的场景中, Master需要避免 错误的去为同一个chunk指定两个Primary , 采取的方式就是租约机制
当指定一个Primary时,Master为它分配一个租约,Primary只在租约内有效。Master和Primary都会存储租约的时间。
当租约过期,Primary会停止响应客户端请求,它会忽略或者拒绝客户端请求。
因此,如果Master不能与Primary通信,并且想要指定一个新的Primary时,Master会等到前一个Primary的租约到期。
Master什么也不会做,只是等待租约到期。租约到期之后,可以确保旧的Primary已经降级,这时Master可以安全的指定一个新的Primary而不用担心出现脑裂的情况。
追加数据
在客户端发送了追加数据的请求之后, Master会返回客户端Primary以及Secondary的信息
客户端会将要追加的数据发送给Primary和Secondary服务器,这些服务器会将数据写入到一个临时位置。
最开始,数据不会追加到文件中。当所有的服务器都返回确认消息已经有了要追加的数据,客户端会通知Primary所有的服务器已经准备完成 , 现在可以开始追加我的数据了。
Primary服务器或许会从大量客户端收到大量的并发请求,Primary服务器会以某种顺序,一次只执行一个请求。对于每个客户端的追加数据请求(也就是写请求),Primary会查看当前文件结尾的chunk,并确保chunk中有足够的剩余空间,然后将客户端要追加的数据写入chunk的末尾。
并且,Primary会通知所有的Secondary服务器也将客户端要追加的数据写入在它们自己存储的chunk末尾。
这样,包括Primary在内的所有副本,都会收到通知将数据追加在chunk的末尾。
但是对于Secondary来说,可能会执行失败,比如
- 磁盘空间不足
- 机器故障
- Primary发出的通知丢包
如果secondary服务器写入成功,会通知Primary服务器,只有当所有的secondary服务器全部写入成功并且成功同志Primary,Primary才会向客户端返回写入成功。
否则就会返回写入失败。
GFS论文中提到如果客户端从Primary得到写入失败,那么客户端应该重新发起整个追加过程。客户端首先会重新与Master交互,找到文件末尾的chunk;之后,客户端需要重新发起对于Primary和Secondary的数据追加操作。
这里如何保证一致性(consistency)?
假如我们现在对于chunk A有三个server
分别为 Primary chunk1 , secondary chunk2 , secondary chunk3 , 他们目前的状态为:
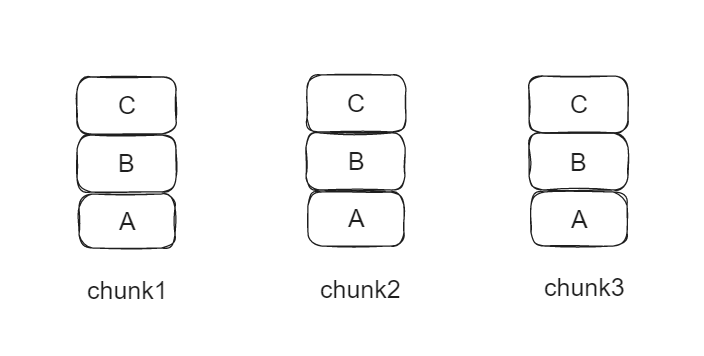
现在客户端发出写请求 , 并且所有的chunk都返回了 准备就绪
这时需要写入一个数据块D, 但是在写入的时候 chunk3发生了未知的异常, 写入失败了 , 那么此时他们的状态为:
这个时候Primary会返回写入失败 , 客户端会准备重试。
涉及的问题
-
chunk3是否会执行恢复?
并不会, 在追加数据失败的场景中, 比如会出现一部分chunkserver追加成功而另一部分失败的情况 , 这种状态对于GFS来说是可以接受的 , 并不需要执行恢复操作 , 这就是GFS的工作方式 , 因为保证强一致性就需要很多额外的操作
-
读chunk会有什么不同?
前面提到客户端会从chunkserver中挑选一个chunk来读取数据 , 但是客户端并不知道是否有某个chunk曾经写入失败了 , 因此会存在读取同一份chunk , 两个客户端或者是两次读取出现数据不一致的情况 , 这个时候取决于具体客户端读取的是哪个chunk
-
是否可以通过版本号来判断(chunk)之前是否有追加的数据?
所有的Secondary都有相同的版本号。版本号只会在Master指定一个新Primary时才会改变。通常只有在原Primary发生故障了,才会指定一个新的Primary。所以,副本(参与写操作的Primary和Secondary)都有相同的版本号,无法通过版本号来判断它们是否一样,或许它们就是不一样的(取决于数据追加成功与否)
-
假如需要追加数据的是一个新文件?
Master节点如果发现客户端请求追加的文件没有关联的chunk。Master节点或许会通过随机数生成器创造一个新的chunk ID。之后,Master节点通过查看自己的chunk表单发现,自己其实也没有chunk ID对应的任何信息。之后,Master节点会创建一条新的chunk记录说,我要创建一个新的版本号为1,再随机选择一个Primary和一组Secondary并告诉它们,你们将对这个空的chunk负责,请开始工作。论文里说,每个chunk默认会有三个副本,所以,通常来说是一个Primary和两个Secondary。










