
线程模型与协程/用户级线程
相信在学习OS的时候都见过这样的一个知识点 :
操作系统线程模型
线程模型是用户线程和内核线程之间的关联方式,常见的线程模型有这三种:
- 一对一(一个用户线程对应一个内核线程)
- 多对一(多个用户线程映射到一个内核线程)
- 多对多(多个用户线程映射到多个内核线程)

这是今天在看Java八股文的时候遇到的, 最开始学习OS的时候是不太清楚用户线程与内核线程的概念的。
后来慢慢学习(Golang)知道了协程的概念。
都知道协程是轻量级的线程,相比线程可以减少大量的上下文切换操作(比如内存映像,Cache等等),并且通过编程语言可以实现方便的调度。
这协程跟上面的用户线程的优点为何如此相似??
揣带着疑问, 这里提出几个问题:
- 资源分配的单位是进程, 调度单位是线程, 那么这里的线程是指的是 用户线程 还是 内核线程 ?
- 假如目前采用的线程模型比例为 内核线程 : 用户线程 = 1:N , 那么这里调度的对象为? 用户线程通过什么调度?
- 假如目前采用的线程模型比例为 内核线程 : 用户线程 = 1:N , 则N中其他的用户线程算什么? 是否是协程?
进程&线程&协程
| 进程 | 线程 | 协程 | |
|---|---|---|---|
| 定义 | 资源分配和拥有的基本单位 | 程序执行的基本单位 | 用户态的轻量级线程,线程内部调度的基本单位 |
| 切换情况 | 进程CPU环境(栈、寄存器、页表和文件句柄等)的保存以及新调度的进程CPU环境的设置 | 保存和设置程序计数器、少量寄存器和栈的内容 | 先将寄存器上下文和栈保存,等切换回来的时候再进行恢复 |
| 切换者 | 操作系统 | 操作系统 | 用户 |
| 切换过程 | 用户态->内核态->用户态 | 用户态->内核态->用户态 | 用户态(没有陷入内核) |
| 调用栈 | 内核栈 | 内核栈 | 用户栈 |
| 拥有资源 | CPU资源、内存资源、文件资源和句柄等 | 程序计数器、寄存器、栈和状态字 | 拥有自己的寄存器上下文和栈 |
| 并发性 | 不同进程之间切换实现并发,各自占有CPU实现并行 | 一个进程内部的多个线程并发执行 | 同一时间只能执行一个协程,而其他协程处于休眠状态,适合对任务进行分时处理 |
| 系统开销 | 切换虚拟地址空间,切换内核栈和硬件上下文,CPU高速缓存失效、页表切换,开销很大 | 切换时只需保存和设置少量寄存器内容,因此开销很小 | 直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快 |
| 通信方面 | 进程间通信需要借助操作系统 | 线程间可以直接读写进程数据段(如全局变量)来进行通信 | 共享内存、消息队列 |
再次来强调一下线程的概念 :
线程是轻量级的进程,在一个进程内部可以存在一个或多个线程,进程与进程之间是不能共享内存的,进程之间的消息通信不方便,
但是一个进程内部的线程之间是共享这个进程的内存空间的,线程之间通信很方便。
这里需要注意一点, 用户线程是位于用户空间中的, 操作系统对此没有感知 , 从内核的角度来看 , 还是按照单独的线程(内核线程)来进行调度
OS线程调度
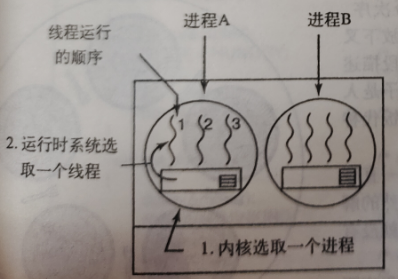
用户级线程
由于内核并不知道有线程存在,所以内核还是和以前一样地操作,
选取一个进程,假设为A, 并给予A以时间片控制。
A中的线程调度程序决定哪个线程运行(比如下面的goroutine调度),
假设为A1,由于多道线程并不存在时钟中断,所以这个线程可以按其意愿任意运行多长时间。
如果该线程用完了进程的全部时间片,内核就会选择另一个进程运行。
内核级线程
现在考虑使用内核级线程。
内核选择一个特定的线程运行,它不用考虑该线程属于哪个进程。
对被选择的线程赋予一个时间片,而且如果超过了时间片,就会强制挂起该线程。
用户级线程和内核级线程之间的差别(在于性能)
用户级线程的线程切换需要少量的机器指令,而内核级线程需要完整的上下文切换(修改内存映像,使高速缓存失效),
这导致了若干数量级的延迟。
另一方面,在使用内核级线程时,一旦线程阻塞在I/O上就不需要像在用户级线程中那样将整个进程挂起。
- 用户级线程: 在用户级线程模型中,线程的调度和管理完全由用户空间的线程库(如pthread库)来完成,这些库是在用户空间中实现的。当用户级线程中的某个线程被阻塞在I/O操作时,由于用户级线程库无法直接进行内核层面的调度,整个进程中的所有用户级线程都会被阻塞。这是因为操作系统并不了解用户级线程的存在,因此无法单独调度某个用户级线程。这导致了用户级线程中的任何一个线程被阻塞都会影响整个进程的执行。
- 内核级线程: 在内核级线程模型中,线程的调度和管理由操作系统内核直接负责。因此,当某个内核级线程被阻塞在I/O操作时,操作系统可以继续调度其他线程来执行,而不会阻塞整个进程(OS可以感知到这里发生了阻塞)。这是因为内核级线程是由操作系统直接管理的,操作系统具有更高的权限和更完善的调度能力,可以更好地处理线程阻塞的情况。
用户级线程-goroutine
配置Go环境
1 | [root@localhost ~]# rpm --import https://mirror.go-repo.io/centos/RPM-GPG-KEY-GO-REPO |
测试代码
下面的代码通过 go 关键字执行方法打印 协程 的PID , 最后打印ps 命令获取到的内容
1 | package main |
go run main.go
1 | [root@localhost test]# go run main.go |
golang中的协程调度
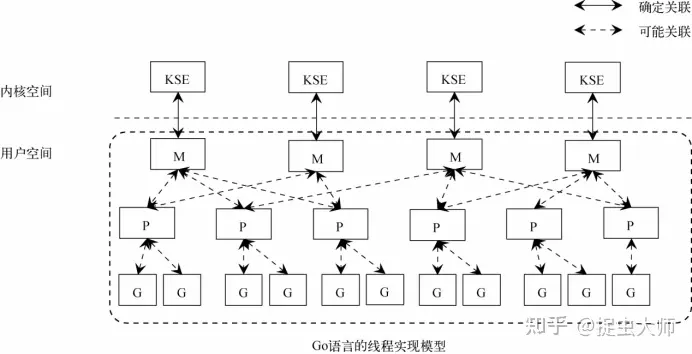
具体参考 : https://golang.design/under-the-hood/zh-cn/part2runtime/ch06sched/mpg/
关于JVM线程模型
对应内核线程
通过代码测试即可
下面的代码会创建1000个Java线程并 sleep10s
1 | public class Main { |
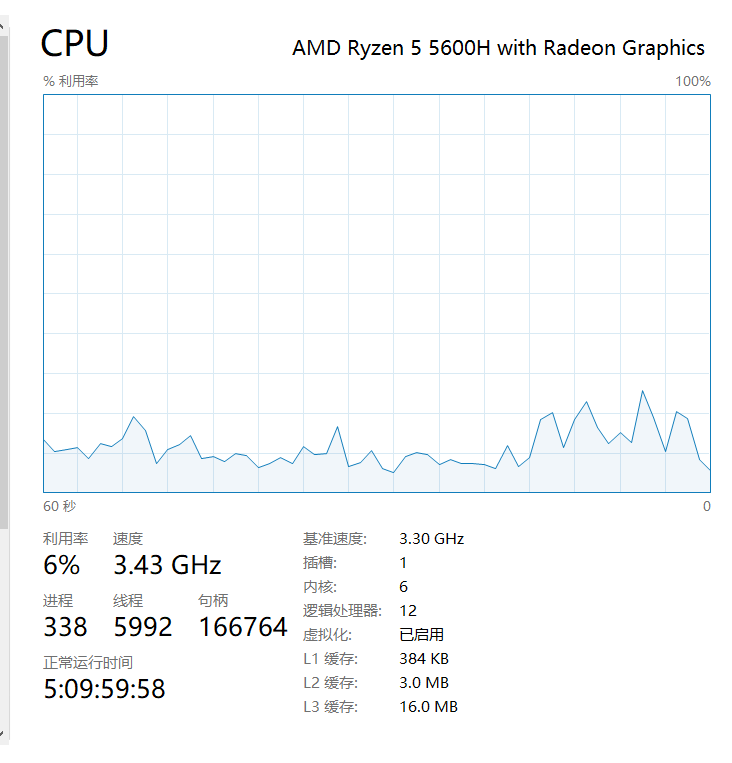
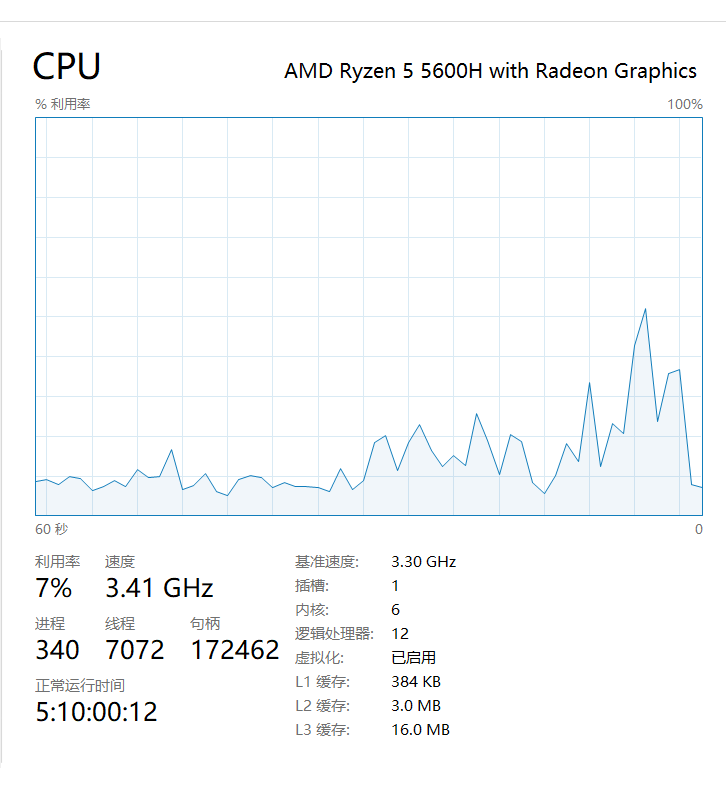
此测试环境是 windows 10 AMD R5 5600H
运行代码, 查看任务管理器-性能
运行之前
运行之后
获取PID-测试代码(JDK8)
对于hotspot VM (Oracle发行的VM, 默认是这个虚拟机实现) , 在 Windows 和 Linux 等主流操作系统中,
Java 线程采用的是一对一的线程模型,也就是一个 Java 线程对应一个系统内核线程。
在 Java 中,线程通常被称为“用户线程”,因为它们是由应用程序的开发者创建和管理的,运行于JVM中。
Java 线程不是直接映射到操作系统的内核线程,而是由 JVM 的线程调度器负责在操作系统线程上进行调度。
JVM 会为线程管理和调度提供一层抽象,从而将与操作系统线程相关的细节隐藏起来,这样能够更好地跨平台。
因此,Java 的线程可以被认为是用户级线程。
当 Java 应用程序的线程在操作系统上运行时,它们实际上是由操作系统的内核线程支持的。然而,Java 的线程是在 JVM 的上层进行调度和管理的,同时也受 JVM 的限制。
比如下面的代码
1 | public static void main(String[] args) { |
两个线程打印出来的 PID是 相同的
1 | 54856@DESKTOP-F5I5LH4 |
获取PID-Docker测试
既然通过代码无法获取线程的PID , 那通过Linux的命令来试一试
由于直接在Linux中运行top / ps 等命令会有其他进程的干扰 , 这里通过Docker来进行
测试代码如下
1 | public class Main { |
准备两个会话 , 分别用来 执行 java程序 以及 统计进程
可以看到 并没有跟预期的那样能看到 创建的java线程对应的内核线程
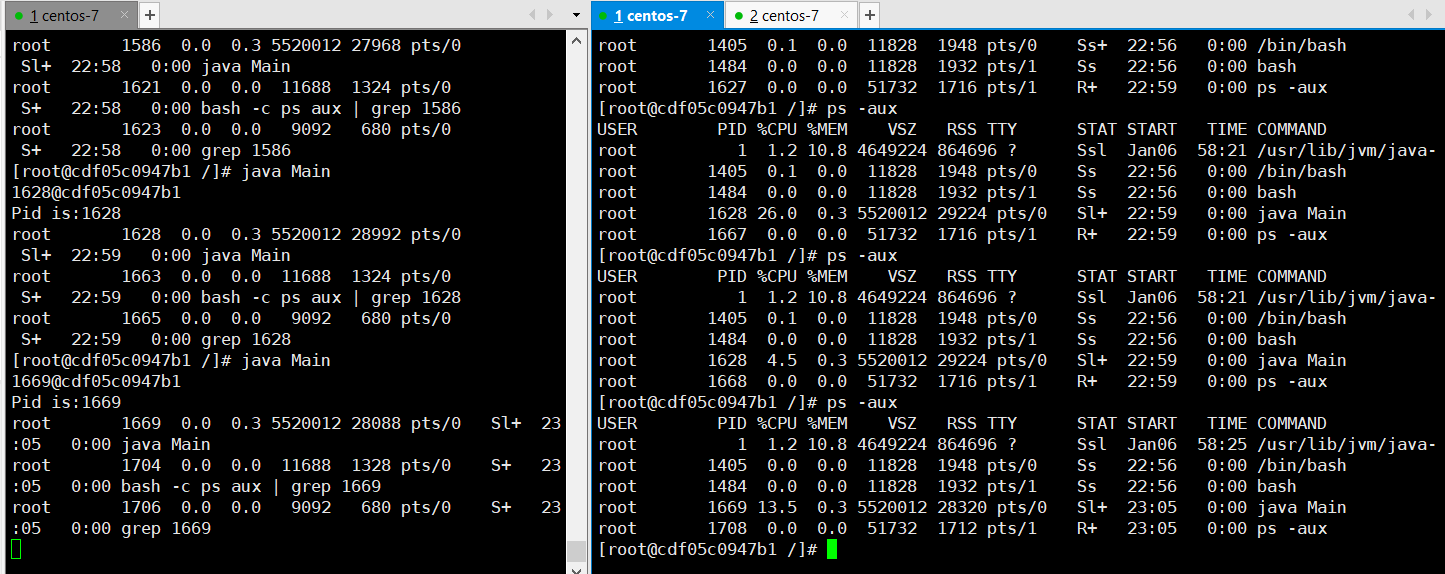
会不会是Docker由于隔离的原因无法找到创建的内核线程呢?
那么我们继续在Linux中直接进行测试
方法是
- 通过
ps -ef |wc -l统计进程的个数 - 运行java程序, 创建20 个线程并sleep 10s
- 再次统计进程的个数
测试结果如下
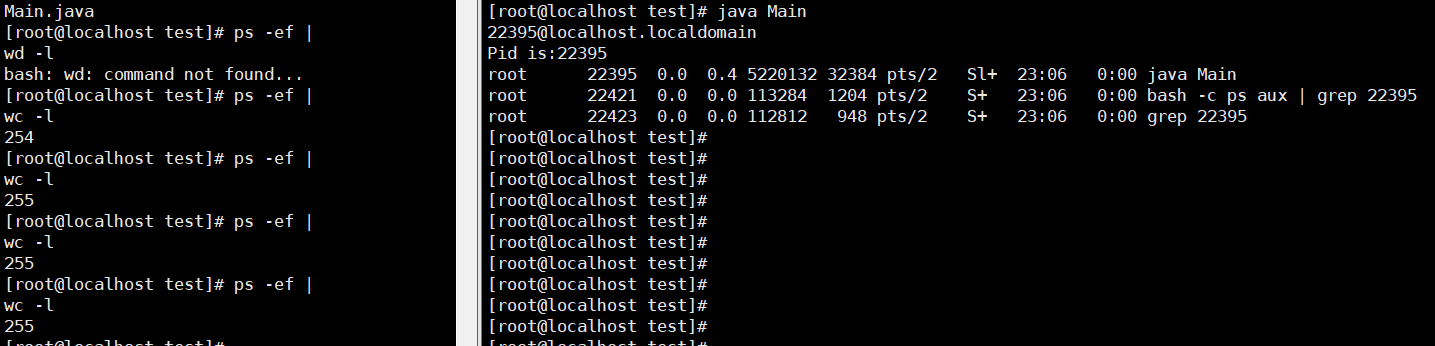
进程数仅仅增加了 1 , 后面又测试了几次 , 还是一样结果。
或许想要搞明白底层的实现只能去看JVM的源码了。。
先到这里为止, JVM的详细执行步骤后面有时间再去探究。
总结
关于最开始的几个问题, 经过简要的搜集, 已经可以得出相应的结论了 :
-
资源分配的单位是进程, 调度单位是线程, 那么这里的线程是指的是 用户线程 还是 内核线程 ? => 内核线程
-
假如目前采用的线程模型比例为 内核线程 : 用户线程 = 1:N , 那么这里调度的对象为? 用户线程通过什么调度?
这种情况下操作系统讲时间片分配到进程(内核线程) , 然后通过 内核线程本身的调度策略来进行调度 , 调度的对象为 用户线程
-
假如目前采用的线程模型比例为 内核线程 : 用户线程 = 1:N , 则N中其他的用户线程算什么? 是否是协程?
其他的用户线程是协程
另外, goroutine本身就是用户级线程的一种实现 , 类似的实现还有:
-
POSIX线程库(pthread):POSIX线程库是一套线程API的标准,适用于UNIX和类UNIX操作系统上的多线程编程。通过pthread库,程序员可以使用函数来创建、管理和同步用户级线程。这种方法是比较底层的,需要程序员手动进行线程的管理和同步。
-
Java线程(Thread类):在Java语言中,线程是通过java.lang.Thread类来表示的。Java提供了高级的线程管理接口,可以通过继承Thread类或者实现Runnable接口来创建线程。Java自己负责管理线程的调度和同步,程序员无需处理线程的底层细节。
虽然说 Java的线程模型是与内核线程1:1 对应, 但是JVM在实现层面屏蔽了这些细节, 实际上还是属于用户级线程。
Reference
- 现代操作系统 第四版
- https://interviewguide.cn/notes/03-hunting_job/02-interview/02-01-os.html
- https://zhuanlan.zhihu.com/p/413218471
- https://www.ganymedenil.com/2019/05/21/go-standard-library-by-get-the-current-process-PID.html
- https://www.zhihu.com/question/410231741
- https://golang.design/under-the-hood/zh-cn/part2runtime/ch06sched/mpg/







